
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Meena
- sbert
- word2vec
- 의미연결망
- 동적토픽모델링
- 머신러닝
- 구글클라우드플랫폼
- ROC-AUC Curve
- Holdout
- dynamic topic modeling
- word representation
- 알파베타가지치기
- Google Cloud Platform
- 감성분석
- 토픽모델링
- 사회연결망분석
- hugging face
- topic modeling
- 임베딩
- semantic network
- Enriching Word Vectors with Subword Information
- sequential data
- 분류모델평가
- degree centrality
- sensibleness
- type-hint
- QANet
- 허깅페이스
- Min-Max 알고리즘
- GCP
- Today
- Total
Dev.log
Attention is All you need 논문리뷰 본문
기계의 성능 발전으로인해 사람의 언어와 같은 sequential data 처리가 가능해지자, 기계를 통해 인간의 언어를 처리하고자 하는 아이디어들이 많이 생겨놨고 이는 인공지능의 자연어 처리의 발전으로 이루어 졌습니다. 자연어처리(Natural language processing, NLP)는 인공지능의 한 분야로써 인간의 언어를 컴퓨터와 같은 기계장치를 통해 처리를 하는일을 의미하며 현재 자연어 처리 및 생성에서 좋은 성능 보여주는 BERT나 GPT-3의 아버지격? 과 같은 모델이 있습니다. 바로 그 모델은 Transfomer이며, transformer는 2017년 Attention is All you need라는 논문에서 소개되었습니다.
1. Transformer의 탄생배경
과거 sequence 데이터를 처리하기 위해서는 recurrent 모델을 많이 사용하였습니다. 왜냐면 recurrent 모델은 $t$번째에 대한 output을 생성하기 위해 $t$번째의 input과 $t-1$번째의 hidden state를 사용해서 문장의 sequential한 특성이 유지된다는 장점을 지니기 때문입니다. 하지만, 이는 long-term dependency에 취약하다는 문제를 지니고 있었습니다. 쉽게 말해 "저는 운동을 즐겨하고 관심이 있어서 요즘 퇴근하고 매일 헬스를 즐겨합니다" 라는 문장을 생성 하는게 모델의 task로 주어졌을 때, recurrent 모델은 운동과 헬스는 서로 주요한 단서임에도 불구하고 두 단어사이의 거리가 가깝지 않아서 운동을 통해 헬스를 생성하기 어렵다는 단점을 지니고 있다는것입니다. 또한 모델의 훈련과정에서 병렬화를 제외시킴으로서 sample간의 배치화를 제한시켜 길이가 길어진 문장일수록 처리하기 어렵다는 단점역시 지니고 있습니다. 이에 Attention is All you need 이라는 논문에서는 transformer 라는 모델을 등장시켜 attention 메커니즘을 사용하여 해당 문제를 해결하였습니다.
2. Transformer모델의 구조
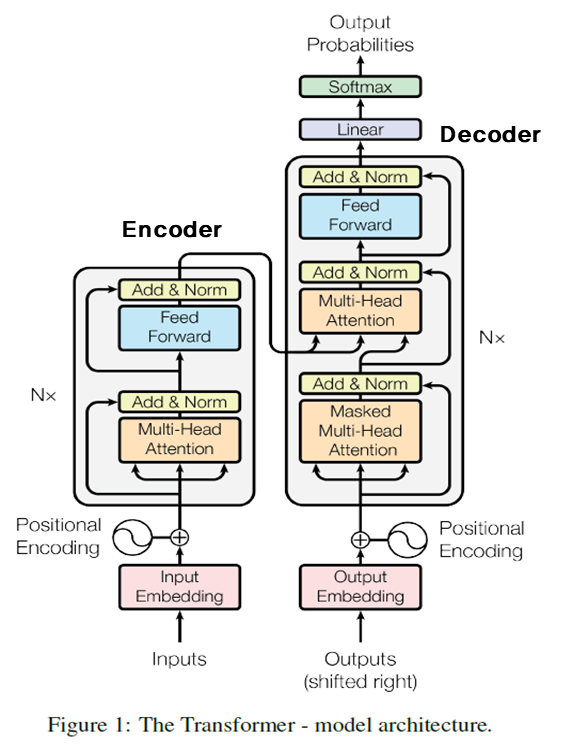
Encoder
Encoder의 경우 N개의 동일한 layer로 구성되어졌습니다. Input $x$가 첫 번째 layer에 들어가게 되고, layer$(x)$가 다시 layer에 들어가는 형식입니다. 또한, 각각의 layer는 두 개의 sub-layer로 구성되어 지는데, 첫번째는 multi-head self-attention mechanism과 두번째는 position-wise fully connected feed-forward network로 이루여져있습니다. 이때 두 개의 sub-layer에 residual connection(input값을 output으로 그대로 전달하는것을 의미합니다. 또한 residual connection은 sublayer의 output 과 input의 차원크기를 맞춰줘야 합니다)을 이용합니다. 이후 에 layer normalization을 적용합니다.
Decoder
Decoder도 N개의 동일한 layer로 구성되어졌습니다. 그리고 encoder의 결과에 multi-head attention을 수행할 sub-layer를 추가합니다. 그리고 sub-layer에 residual connection을 사용한 뒤, layer normalization을 적용시켜 줍니다. 또한 decoder 영역에서는 순차적으로 결과를 생성해야 하기 때문에 masking이란것을 진행하여 줍니다. 이를 통해 position $i$ 보다 이후에 있는 position에 attention을 못하게 함으로써, position$i$를 예측 할 때는 미리 정보를 가지고있는 output에게만 depandent하게 됩니다.
Attention
Attention은 '특정 정보에 좀더 주의하라' 라는 의미를 닮고 있습니다. 즉, 모델이 수행해야 하는 테스크가 "저는 운동을 즐겨하고 관심이 있어서 요즘 퇴근하고 매일 헬스를 즐겨합니다" 라는 문장을 영어에서 한국어로 번역한다고 가정했을 때, 모델은 운동을 이라는 token을 decode할 때 source에서 work-out 이 가장 중요하게됩니다.
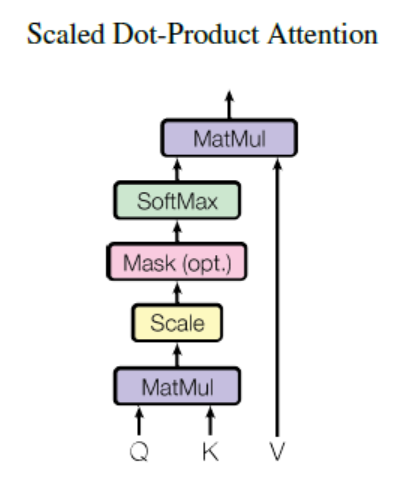
본 논문에서 attention을 Scaled Dot-Product Attention을 의미하는데, 이는 input이 $d_k$ 차원의 query와 key들과 $d_v$ 차원의 value들로 구성되어집니다. 이 때, 모든 query와 key들에 대한 dot-product를 계산하며, 각각 ${\sqrt{d_{k}$로 나누어 줍니다. 즉, dot-product 이후 ${\sqrt{d_{k}$로 scaling을 해주기 때문입니다. 여기서 ${\sqrt{d_{k}$로 scaling을 해주는 이유는 dot-product값이 증가될 수록 softmax 함수에서의 기울기의 변화가 거의 없기 때문입니다.$$ Attention(Q,K,V) = softmax(\frac{QK^{t}}{\sqrt{d_{k}}}) $$ 또한, 각 key와 value들은 같은 값을 갖게 되고 query와 key에 대한 dot-product를 계산 했을 시, 둘에 대한 similarity를 구할 수 있게 됩니다. 더 나아가 softmax가 계산된 값을 value에 곱해준다면, query와 유사한 value일수록 높은 값을 지니게 됩니다.
Multihead attention의 경우 아래의 수식과 같이 표기됩니다.
$$ Multihead(Q,K,V) = Concat(head_1,...,head_n)W^o $$ $$where$$ $$head_i = Attention(QW_i^Q,KW_i^K,VW_i^V)$$
3. 결론
Transformer 라는 모델은 attention 메커니즘을 사용하여 sequential data를 빠르고 정확하게 처리할 수 있게 되었고, encoder와 decoder에서 attention을 사용하여 병렬화 작업이 가능해 졌습니다
'논문리뷰' 카테고리의 다른 글
| RoBERTa 논문리뷰 (0) | 2022.03.08 |
|---|---|
| QANet 논문리뷰 (0) | 2022.03.07 |
| Glove 논문리뷰(수정중) (0) | 2022.03.07 |
| Neural Probabilistic Language Model 논문리뷰 (0) | 2022.03.05 |
| FastText 논문리뷰 (0) | 2022.03.04 |



