
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 감성분석
- hugging face
- 사회연결망분석
- 구글클라우드플랫폼
- Min-Max 알고리즘
- 알파베타가지치기
- 임베딩
- 동적토픽모델링
- 허깅페이스
- 의미연결망
- topic modeling
- sensibleness
- Meena
- dynamic topic modeling
- sbert
- sequential data
- QANet
- word2vec
- semantic network
- 분류모델평가
- GCP
- degree centrality
- Enriching Word Vectors with Subword Information
- Holdout
- type-hint
- ROC-AUC Curve
- word representation
- Google Cloud Platform
- 토픽모델링
- 머신러닝
- Today
- Total
Dev.log
ElECTRA 논문 리뷰 본문
본 포스팅에서는 ELECTRA(Efficiently Learning an Encoder that Classfies Token Replacement Accuratly)에 대해 리뷰해 보도록 하겠습니다. 먼저, ELECTRA가 등장하기전 SOTA의 language model이 이용한 방식인 MLM(Masked Language Modeling) 방식에 대해 설명드리도록 하겠습니다.
MLM(Masked Language Modeling)
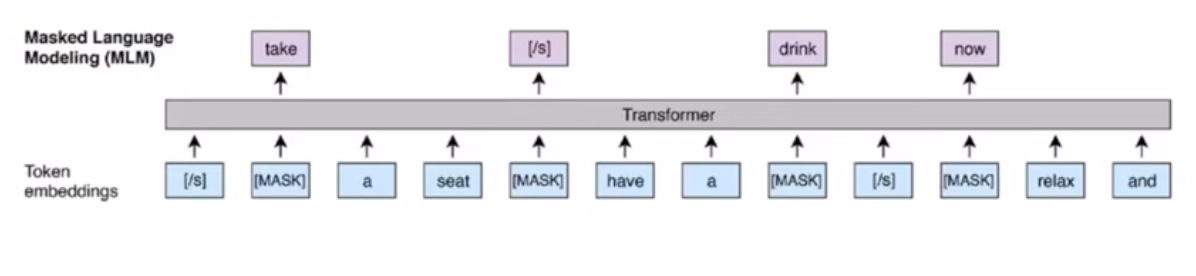
MLM방식은 주어진 문장 토큰들 중 전체의 15%만큼 마스킹을 하여 해당 토큰을 모델이 볼 수 없게한 뒤, 그 마스킹된 토큰의 원래 토큰을 맞추는 형식으로 학습이 도비니다. 하지만, 이는 마스킹된 토큰에 대해서만 학습이 이루어지기 때문에 주어진 예시의 15%정도밖에 사용을 하지 못하여 많은 양의 연산이 필요하였습니다.
Replaced token detection

따라서 ELECTRA모델에서는 Replaced token detection이라는 방식을 사용하게 되는데, 이는 위의 ELECTRA방식의 전반적인 구조인데 generator와 discriminator 두가지 모델이 같이 학습하게 됩니다. generator모델은 the와 ate와 같이 주어진 문장에서 마스킹된 위치에 올 수 있는 토큰을 generator가 예측을 하게 되고, discriminator는 generator가 마스킹된 문장을 채운 문장을 입력값으로 받아서 각 위치가 generator의 인풋으로 대체 되었는지를 맞추는것으로 학습이 진행 됩니다. 해당 방식은 MLM과는 다르게 모든 토큰의 대체 여부를 학습하기 때문에 모든 인풋 토큰으로 부터 학습이 진행되며, 제네레이터가 토큰을 실제로 생성하지는 않기 때문에 adversarial하지 않다고 볼 수 있습니다.
ELECTRA

위의 그림은 ELECTRA모델의 전체 loss 함수 입니다. 두가지로 나누어 지게 되는데, 첫번째 부분은 제네레이터 부분의 likely-hood loss로 MLM방식과 비슷한 loss를 사용하게 되고 디스크리미네이터 loss의 조합으로 학습이 진행되는것을 확인 할 수 있습니다. 이때 sampling이라는 요소 때문에 디스크리미네이터의 loss는 제네레이터 까지 back propogate되지 않습니다.
ELECTRA - Generator(Mask)

ELECTRA - Generator(Replacing)
다음은 제네레이터에서 마스크를 씌우는 과정입니다. 위의 그림에서 붉은 상자로 표시된 제네레이터의 인풋은 $$x^{mask}$$로 마스크 할 위치인 $$m$$에 따라서 input문장에 mask를 씌운것 입니다. 이때 마스크할 $k$개의 위치는 1에서 $$n$$까지의 위치중 uniform distribution으로 $$k$$개가 선택되는 것으로 만들어 지게 됩니다
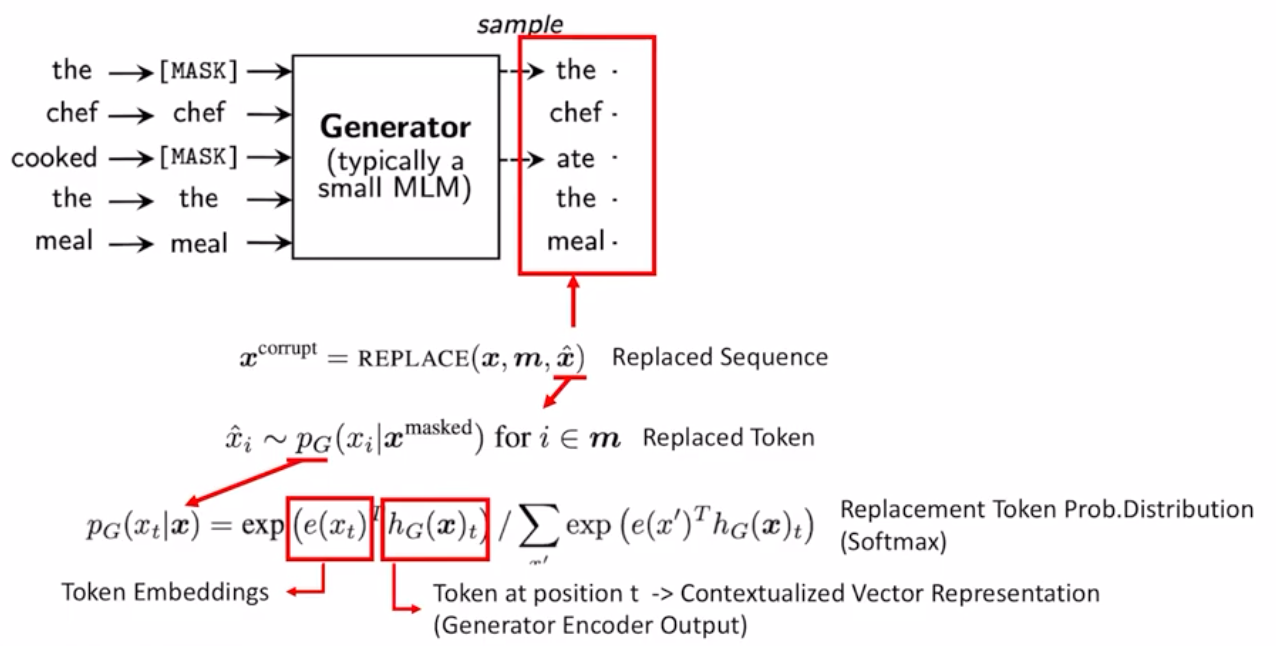
다음은 제네레이터의 아웃풋인 마스킹된 위치를 replacing하는것입니다. 오른쪽 상단의 붉은 색으로 표시된 제네레이터의 아웃풋은 마스킹된위치를 토큰 x^ 으로 교체한것입니다. 이때 교체된 토큰은 각 위치 i당 제네레이터 아웃풋인 PG 확률에 의해서 결정이 됩니다. 이 확률은 전체 보케뷸러리 사이즈의 softmax 아웃풋이라 생각하면 됩니다. 계산 식을 보면은 각 토큰의 임베딩 값과 해당 위치의 제네레이터의 인코더 아웃풋값과 내적한것의 softmax를 적용한 것임을 알 수 있습니다.
ELECTRA - Generator(Loss)

다음은 제네레이터의 loss인데, 각위치에서 정답 토큰의 확률값에 로그를 씌운 maximum likelihood로 학습이 되는것을 볼 수 있습니다.
ELECTRA - Discriminator
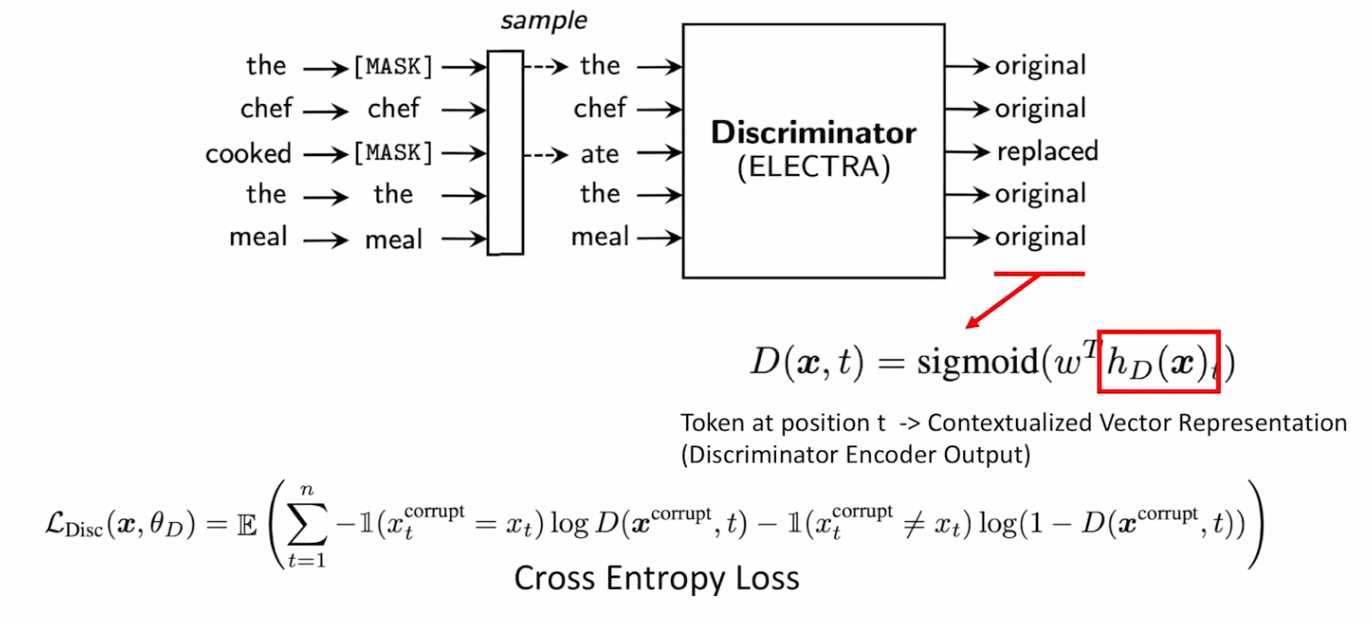
다음은 디스크리미네이터의 그림입니다. 디스크리미네이터는 제네레이터에서 마스킹것이 대체된 토큰 들을 인풋으로 받아서 각토큰이 교체되었는지 여부를 디스크리미네이터 인코더의 아웃풋인 hd(x)를 fully-connected layer를 거친후 sigmoid activation function을 적용하여 예측하게 됩니다. 이때 loss의 경우 cross entropy를 이용하여 학습됩니다
성능비교

ELECTRA가 나온 시점에서 다른 language model들과 GLUE score를 기준으로 비교하게 되면, ELECTRA가 적은양의 연산으로 좋은 performace를 보여주는것을 확인 할 수 있습니다. 또한 성능이 가장 좋은 XLNet과 비교를 하였을떄, 훨씬 적은 연량으로 학습이 되는것을 볼 수 있습니다.

또한 위의 그림과 가티 BERT와 비교하였을때, 같은 히든 사이즈 일때 그리고 같은 학습량일때의 성능이 ELECTRA에서 월등히 향상된것을 확인 할 수 있습니다. BERT와 성능차이를 확인하기위해 본논문에서 실험한 pre-training object에 대한 변화 실험은 총 3가지로 이루어졌습니다.
- ELECTRA 15% : ELECTRA와 동일하지만 마스크를 씌운 토큰 위치의 loss만 이용
- Replace MLM : 디스크리미네이터가 기존 MLM과 동일한 방식으로 학습이 되지만, 기존 MLM의 인풋에 마스킹된 위치키에 마스크 토믄이 들어갔다면, 여기서는 제네레이터가 생성한 토큰이 들어간 후, 디스크리미네이터가 마스킹된 위치의 토큰을 예측하는 방식입니다. 이는 BERT의 문제점중 하나였던 pre-training때 마스크 토큰이 존재하지만 fine-tuning때 존재하지 않는다는 문제점과의 연관성 확인을 위해서 입니다.
- All Tokens MLM : Replace MLM과 유사하지만, masking된 위치 뿐만 아니라 모든 위치의 토큰에 대해서 예측하게됩니다.

위의 차트는 각 object들에 대한 성능 분석인데, ELECTRA 15%와 Replace MLM은 BERT에 비해서 성능 향상이 미비한것을 확인 할 수 있습니다. 이에 대해서 본 논문의 저자들은 BERT에 비한 성능향상은 마스킹된 15%뿐만아닌 모든 인풋에서 학습하는 방식이 좀더 효율적이라 판단 하였습니다. 따라서 All-Tokens MLM, 즉 모든 인풋에 대해서 학습이 이루어지는 경우 성능이 ELECTRA에 좀더 근접한것을 볼 수 있습니다.
'논문리뷰' 카테고리의 다른 글
| Towards a Human-like Open-Domain Chatbot (0) | 2022.05.16 |
|---|---|
| RoBERTa 논문리뷰 (0) | 2022.03.08 |
| QANet 논문리뷰 (0) | 2022.03.07 |
| Glove 논문리뷰(수정중) (0) | 2022.03.07 |
| Neural Probabilistic Language Model 논문리뷰 (0) | 2022.03.05 |


