
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Enriching Word Vectors with Subword Information
- degree centrality
- dynamic topic modeling
- ROC-AUC Curve
- 토픽모델링
- 감성분석
- 분류모델평가
- QANet
- 동적토픽모델링
- hugging face
- Meena
- word representation
- 구글클라우드플랫폼
- 의미연결망
- Min-Max 알고리즘
- Holdout
- 머신러닝
- sensibleness
- sequential data
- sbert
- type-hint
- 알파베타가지치기
- Google Cloud Platform
- semantic network
- word2vec
- topic modeling
- 임베딩
- 허깅페이스
- GCP
- 사회연결망분석
- Today
- Total
Dev.log
Towards a Human-like Open-Domain Chatbot 본문
본 포스팅에서는 Google brain research team에서 발표한 Towards a Human-like Open-Domain Chatbot이라는 논문에 대해 리뷰해 보도록 하겠습니다. 이 논문은 2020년 2월 경에 발표됨과 동시에 주목을 받게되었는데, 이는 end-to-end의 generation 모델로 이전 모델에 비해 압도적으로 높은 수준의 대화를 구현했고, 거의 인간 수준에 맞먹는 대화 실력을 보여 주었기 때문입니다.
Towards a Human-like Open-Domain Chatbot이라는 제목에서 확인할 수 있듯이, 본 논문에서는 크게 두가지 챕터로 이루어 진다고 할 수 있습니다. 첫번째로 챗봇이 사람과 같은 대화를 추구한다고 할 때(human-like), 이를 평가할수 있는 척도에 대해 소개를 하고, 사람과 같은 대화를 할수 있는 챗봇인 Meena(Open-Domain Chatbot)에 대해 소개를 합니다.
챗봇 평가
1. Sensibleness
본 논문에서는 챗봇과의 대화가 얼마나 사람과 유사한지를 평가하는 평가방법에 대해 소개를 했습니다. Sensiblness 값은 챗봇이 대화의 맥락에 따라 일관적이고 논리적이며, 사실에 기반한 대화를 하는가를 측정하는 척도라고 할 수 있습니다. 즉, 챗봇과의 대화의 흐름이 자연스러우며, 일관적인지의 여부를 판단하는것이기 때문에 객관적이기도 합니다. 한가지 예를들어 보겠습니다.

위의 그림과 같은 대화에서 챗봇이 답한 1번 대답의 경우, 대화에 흐름에 맞고 일관적인 대답을 하였기 때문에 sensibleness 값이 1이 되게 됩니다. 반면, 챗봇이 무슨 빵을 좋아하는지를 묻는 질문에서 2번 답과 같이, "난 빵 안좋아해"와 같이 대답을 한다면, 해당 답은 논리적 혹은 맥락적이지 않기 때문에 sensibleness 값을 0을 가지게 됩니다. 이러한 sensiblness 평가 방식은 대화의 맥락에 대해 일관직이고 논리적인지 판단할 수 있는 지표가 될 수 있지만, 챗봇의 '사람다움'을 평가하기에는 한계를 지니고 있습니다. 예를 들어, 의문문에는 '모른다' 라고 대답을 하고 평서문에서는 '응' 과 같은 대답을 한다면, 이러한 대답들은 대화의 논리나 흐름을 해치는것은 아니기 때문에 sensiblness에서 높은 점수를 받을수 있는 반면, 그 대답이 단조롭고 일반적이라는 한계를 지니고 있습니다. 따라서 이러한 한계를 보안하기위해 specificity라는 평가척도가 등장하게 되었습니다.
2. Specificity
Specificity는 대화의 흐름에 알맞으면서도, 대화와 관련이 있는 다양한 대답을 하는가에 대한 평가 척도라고 할수 있습니다. 예를들어 아래와 같은 대화에서, 1번 대답의 경우 대화의 맥락에는 맞는 반면, 대화의 패턴이 단조롭고 일반적이라고 할 수 있기 때문에 sensiblness의 경우 1이되지만 specificity의 경우 0이 됩니다. 반면 챗봇의 2번 대답은 대화의 맥락과 일관성을 유지하는 동시에 사람과 같이 주제에 더 확장된? 대답으로 볼 수 있기 때문에 sensiblness의 값과 specificity의 값 모두 1을 가지게 됩니다.

3. SSA
SSA는 챗봇의 human-like, 즉 사람다움을 평가하는 지표로써 sensibleness와 specificity의 평균을 통해 도출이 됩니다. 즉, 평가자들이 챗봇의 대화를 보고 sensiblness값과 specificity값을 평가하여 낸 평균이 SSA값이라고 할 수 있습니다. 이때 sensiblness값이 1을 가지는 경우에는 specificity를 평가하지만, sensiblness값이 0이라면 specificity도 0으로 평가가 됩니다. SSA평가방식은 여러 사람이 평가 하더라도 결과가 비교적 일관적이라는 장점을 지닙니다. 특히 specificity의 경우에는 주관적인 판단이기 때문에, 평가자마다 평가 결과가 엊갈릴수 있습니다. 이를위해 sensiblness를 결과를 계산한 결과 아래 그림과 같은 결과를 보여주었으며, 이러한 수치는 평가가 객관적임을 보장할 수 있는 수치라고 논문에서는 언급을 하고 있습니다. 두번째로는 SSA값이 대화를 평가하는 proxy로써 활용이 가능하다라는 것입니다. 평가자들이 사람과 챗봇간의 대화보고, 해당 대화가 얼마나 사람같은가를 평가를 하였을때 그값과 SSA값의 상관관계가 높은것을 확인 할 수 있습니다.

이 논문에서는 크게 두가지 방법으로 챗봇을 평가합니다. 첫번째 평가방식은 static evaluation으로 1개에서 3개의 turn으로 이루어진 1477개의 대화 문맥을 미리 정해두고 그 문맥에 알맞은 대화를 하도록 한 뒤, 이를 평가하는 방식입니다. 그러나 이러한 평가 방식은 주어진 데이터셋에 의해서 편향된 대답이 나올수 있습니다. 따라서 이를 보안하기위해 interactive한 평가가 함께 진행이 됩니다. interactive evaluation의 경우에는 실험자와 챗봇이 1대1로 대화를 하는데, "hi"라는 말과함께 대화를 시작하게 됩니다. 도메인이나 주제에 대한 제한은 없고 한 대화당 최소 14개에서 최대 28개의 턴으로 구성된 대화를 진행하게 됩니다. 각 챗봇마다 100개의 대화를 수집하고 이를 바탕으로 Sensibleness와 specificity를 평가하게 됩니다.
Meena
챗봇은 크게 closed domain 챗봇과 open domain 챗봇으로 구분 할 수 있습니다. Closed-domain 챗봇같은 경우에는 특정 목표를 달성 하기 위해서 키워드나 사용자의 intent에 의해 적절한 반응을하며 대화를 하는것을 목표로 합니다. 우리가 흔히 티켓이나 식당을 예약할때 도와주는 챗봇과 같은 고객응대서비스와 같은 챗봇이 이에 해당된다고 할 수 있습니다. 이에 반해 Open-domain 챗봇은 특정한 목적없이 불특정한 대화의 주제에 대해서 사람처럼 대화를 하는 챗봇입니다. 우리는 이러한 open-domain 챗봇에게 인간과 같은(human-like) 기능을 기대하고 있습니다. 본 논문에서 소개된 Menna라는 챗봇은 이러한 open-domain 챗봇에 해당하게 됩니다.
챗봇의 구조에 따라 챗봇을 구분할 수 있습니다. 첫번째로는 복잡한 프레임워크(Complex framework)를 사용하는 챗봇인데, 이 챗봇은 연구자들이 설계한 여러가지 복잡한 요소들의 결합을 통해서 챗봇이 사용자의 인풋에 대해 적잘한 대답을 할 수 있도록 만드는 것 입니다. 한 논문에서는 하나의 챗봇을 만들기 위해, 언어 이해, 대화처리, 외부와의 커뮤니케이션, 반응생성과 같은 여러 요소가 필요합니다. 이와달리 end-to-end 방식은 큰 뉴럴넷 모델을 사용하는 방식입니다. End-to-end 방식에서는 복잡한 프레임워크 없이 사람과 같은 대화, 즉 오픈 도메인에서 multi turn이 가능한 대화를 하기위해서 데이터를 학습시켜 챗봇을 만드는 방식입니다. 이러한 방식의 성능을 높이기위해서 크게 2가지 방법을 사용하게 되는데 첫번째로는 학습데이터와 파라미터를 추가시켜 큰 end-to-end 모델을 만드는 방식이고 두번째로는 end-to-end 모델의 챗봇을 위한 요소(componet)들을 결합하는 방식입니다. Menna 챗봇의 경우 첫번째 방식인 파라미터와 학습데이터를 많이 추가시켜 큰 end-to-end 모델을 생성하는 방식을 채택 하였습니다. Menna는 아래와 같은 데이터를 사용하였습니다.
- 필터링을한 social media conversation
- 8억 6천 7백만개의 (Context, response) 쌍
- 341GB의 텍스트 및 400억개의 단어
또한 social media conversationdmf 필터링 할 때의 조건은 다음과 같습니다.
- Subword의 수가 2개이하 혹은 128개 이상일경우
- 알파벳으로된 단어가 70% 미만인 경우
- URL을 포함한 메세지의 경우
- 닉네임이 bot을 포함하는 경우
- 메세지가 100번이상 반복되는 경우
- 상단 메세지와 n-gram이 곂지는 비율이 높은 경우
- 안전하지 않거나 공격적인 메세지가 포함되는 경우
- 상단메세지가 인용된 부분의 경우 삭제
- 상단 메세지가 삭제되면 그에 대한 대답들도 모두 삭제
Menna 챗봇의 모델 구조는 Evlovled Transformer seq2seq 모델을 사용하였으며, 해당 모델에 대한 자세한 내용은 아래에서 확인 할 수 있습니다. Evolutionary NAS 구조 + Transformer 기반으로 설계되었으며, 1 ET encoder block 과 13개의 ET decoder block으로 구성되었습니다. 또한 perlexity의 경우 10.7이며 32개의 attention head를 지니고 있습니다. Menna는 학습을 진행 할때 TPU-v3 Pod를 통해 30일을 진행하였으며, 26억개의 파라미터를 사용하였으며 164번의 에폭을 돌렸습니다.
디코딩 부분에 있어서, 기존 뉴럴넷 기반의 대화모델이 일반적이고 단조로운 대답을 내놓는 경향이있다고 본 논문에서는 지적을 했습니다. 이를 보안하기위해 Menna 챗봇은 sample and ranking 디코딩 방식을 사용하였습니다. 이 디코딩 방식은 beam-search 디코딩방식과 비교해서 더욱 풍부한 문장을 보여주는것을 확인 할 수 있습니다

또한 기존의 Menna 챗봇의 문제를 보안해서 만든 Menna(Full) 버전의 경우에는 더욱 다양한 대답을 얻기위해 디코딩 방식을 조정하였으며, 또한 이전의 대답과 비슷한 답변의 경우 후보군에서 제외하는 방식으로 디코딩 방식을 수정하여, 기존 Menna의 베이스 모델에서 발생되는 반복문제를 해결하였습니다. 그리고 민감하고 예민한 이슈를 필터링하기위해 classifier 레이어를 하나더 추가 하였습니다.
결과
Meena 챗봇의 평가에 대해서는 아래의 표에서 확인 할 수 있듯이, 사람과 사람간의 대화보다는 성능이 떨어지는 반면, 다른 open-domain 챗봇들의 성능에 비해서는 성능이 높다는 것을 확인 할 수있습니다.

또한 아래의 문장은 Meena 챗봇과 사람간의 대화인데, 학습데이터에서 존재하지 않는 joke를 생성해낸 것을 확인 할 수 있습니다.

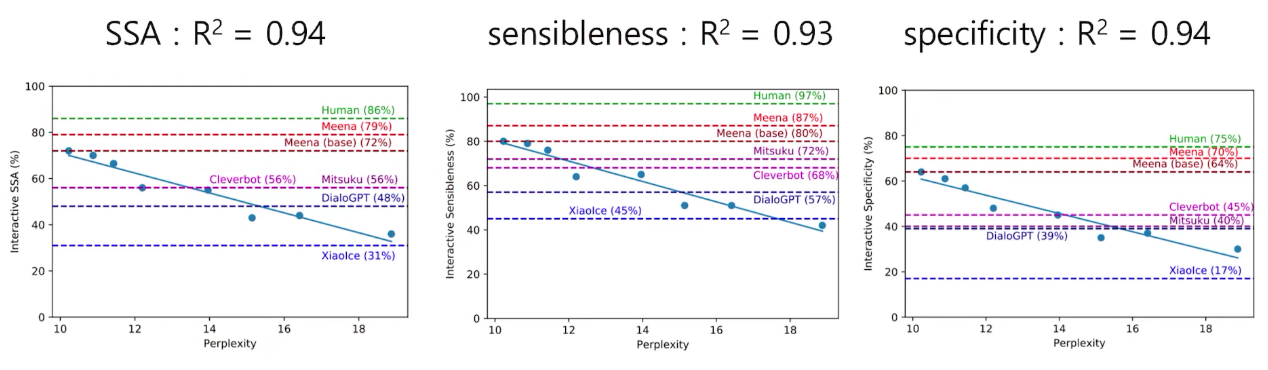
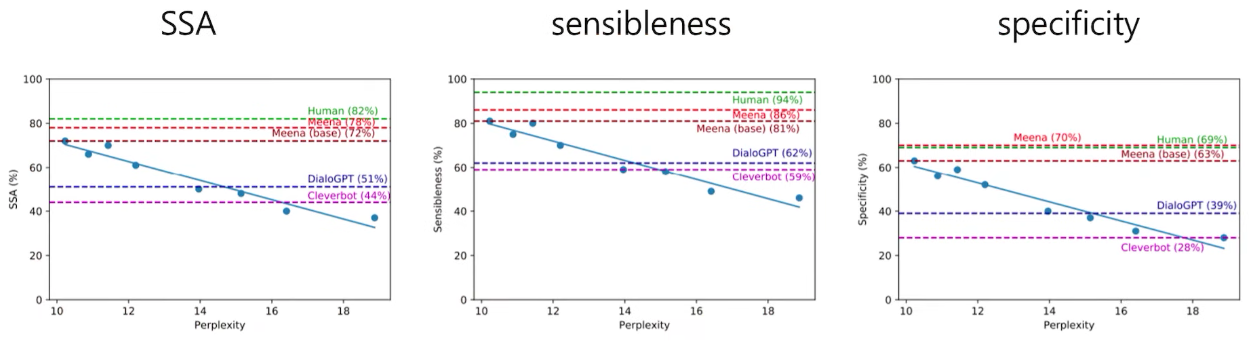
또한 본 논문에서 평가 척도로 설정을한 SSA와 perflexity간의 상관관계에서도 아래 차트에서 확인 할수 있듯이, 동적인 평가와 정적인 평가 모두에서 SSA와 perflexity가 높은 상관관계가 있다는 것을 확인 할수 있었습니다.
'논문리뷰' 카테고리의 다른 글
| ElECTRA 논문 리뷰 (0) | 2022.03.10 |
|---|---|
| RoBERTa 논문리뷰 (0) | 2022.03.08 |
| QANet 논문리뷰 (0) | 2022.03.07 |
| Glove 논문리뷰(수정중) (0) | 2022.03.07 |
| Neural Probabilistic Language Model 논문리뷰 (0) | 2022.03.05 |



