
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- topic modeling
- ROC-AUC Curve
- degree centrality
- 감성분석
- 머신러닝
- GCP
- sbert
- semantic network
- 토픽모델링
- 분류모델평가
- QANet
- type-hint
- 허깅페이스
- word representation
- Meena
- 의미연결망
- 임베딩
- 사회연결망분석
- sensibleness
- 구글클라우드플랫폼
- Holdout
- Min-Max 알고리즘
- 동적토픽모델링
- hugging face
- Google Cloud Platform
- word2vec
- Enriching Word Vectors with Subword Information
- 알파베타가지치기
- dynamic topic modeling
- sequential data
- Today
- Total
Dev.log
Semantic Network Analysis 본문
본 포스팅에서는 sematic network analysis인 의미연결망 분석에 대해 포스팅을 진행해 보도록 하겠습니다. 현재는 인터넷의 대중화로 인해 인터넷에서 생성된 데이터는 대중의 인식이나 트랜드를 추정할 수 있는 방법으로 사용 할 수 있습니다. 이에 사회의 시스템구조를 파악하기 위해 사람, 사물, 조직 간의 관계를 네트워크 관점에서 분석하는 social network analysis(사회연결망분석)을 활용 할 수 있습니다.
Semantic Network Analysis
의미연결망은 이러한 사회연결망 방법을 커뮤니케이션 메시지에 적용시킨 방법입니다. 즉, 의제에 관해 거시적인 틀에서 분석하는 방법으로 개별적인 키워드 위치와 역할을 파악함으로써 기존의 의제 설정모델을 체계적으로 파악 할 수 있게 도움을 줄 수 있습니다. 이때 각 단어들은 노드로 표 현되며, 각각의 노드들은 단어 간 거리와 공출현등을 통해 서로 연관성을 갖습니다.
또한 각 노드 간의 연결성을 발견하기 위해 중앙성(centrality)이라는 지표가 사용할 수 있는데, 이러한 중앙성에 대한 개념은 지역 중앙성과 전체 중앙성으로 구분할 수 있으며 하나의 노드가 다른 노드들에 비해 높은 연결성을 지닐수록 높은 지역 중앙성을 가진 노드로 판별되며 한 노드가 전체적 인 연결망에서 전략적으로 중요한 위치에 있는 경우 높은 전체 중앙성을 가진 노드로 판별할 수 있습니다. 중앙성은 크게 연결 중앙성, 매개 중앙성, 근접 중앙성 으로 나누어 지며 각 중앙성에 대한 정의는 아래와 같습니다.
| 중앙성 지표 | 설명 |
| Degree centrality |
연결정도(degree)를 사용하여 중앙성을 파악합니다. 연결정도는 한 개의 노드가 다른 노드들과의 연결정도를 수를 사용하여 표현한다. 이 때 중앙성은 엣지(edge)의 방향에 따라 중앙성의 값이 다르게 나타 날 수 있다.
|
| Closeness centrality |
한 점의 전체 중앙성을 표현하는 지표로써 다른 노드간의 근 접성을 통해 계산되어진다. 근접성을 나타내는 거리는 두 노 드를 연결하는 최단거리를 지칭한다. 경로거리의 합산이 작을 수록 근접 중앙성이 높아지며, 네트워크의 중심에 위치한다고 확인 할 수 있다.
|
| Betweeneness centrality |
노드와 노드간의 연결에 있어서 한 노드가 다른 노드 사이에 위치하는 정도를 측정하는 개념으로써, 최단 경로에 위치할수 록 매개 중앙성이 높아진다고 할 수 있다
|
Semantic Network Analysis 활용한 연구동향 분석
Semantic network analysis 분석에 앞서, 분석에 필요한 패키지를 설치해주도록 합시다. 만일 패키지가 설치가 안되어있다면 pip install 명령어를 통해 설치를 진행 할 수 있습니다.
import numpy as np
import pandas as pd
import re
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer이후 한국어 자연어 분석을 위한 패키지인 PyKomoran을 임포트해줍니다.
from PyKomoran import *
komoran = Komoran("STABLE")이제 데이터를 불러와줍니다. 해당 데이터는 KCI 내 창업금융을 키워드로 크롤링을 진행하였습니다.
df = pd.read_csv('/Datasets/datasets.csv')
데이터를 불러왔다면 분석을위한 전처리를 진행해주도록 합시다.
#초록이 비어있거나 중복된 항목 삭제
df = df.dropna(subset=['abstract'])
df = df.drop_duplicates(subset='abstract')
# 제목 + 내용 통합
df['contents'] = df.apply(lambda x:x['title']+"\n"+x['abstract'],axis=1)
df['tokens'] = df['contents'].progress_map(lambda x:morp(x))# 불용어 리스트 만들기
stopwords = ['아래','이것','저것','그것','돋움','신명', '태명', '한컴', '돋움','연구', '초록', '스타트', '업',
'동안','거기','저기','여기','대부분','누구','무엇','고딕','만큼','굴림','감사','건지','텐데',
'그간','그건','그때','글쓴이','누가','니다','다면',
'하다','이다','되다','같다','궁','자체','서체','정','서','이','을','있다','없다', '체','관련',
'현재', '진행', '사람', '마음', '남산', '내용', '현실','음','막','김','변','조',
'지금','주변','대상','부분','요즘','하루','마련','시간','이상','행위',
'활동','구분','사실','과정','모습','기간','선정','단지','자신','발생','지역','기대','마련',
'장소','현황','개선','방안','문의','답변','일동','요청','담당자','직원','방법','사용','활용','확인','방식',
'기업', '창업', '금융', '위하다', '보다', '대상', '하다', '있다', '대하다', '따르다', '관련',
'미치다', '통하다', '필요', '크다', '우드', '이후', '관하다', '나타나다','같다']
stopwords_set = set(stopwords)
df['tokens'] = df['tokens'].map(lambda x:[w for w in x if not w in stopwords_set])
이후 TF-IDF와 코사인 유사도로 이루어진 term-term 매트릭스를 생성하기위해 TF-IDF를 계산해주도록 합시다.
###TFIDF###
tfidf_vectorizer = TfidfVectorizer(analyzer='word',
lowercase=False,
tokenizer=None,
preprocessor=None,
min_df=5,
ngram_range=(1,2), #한국어
smooth_idf=True,
max_features=1000
)
tfidf_vector = tfidf_vectorizer.fit_transform(df['tokens'].astype(str))Semantic network analysis를 위해 TF-IDF를 기준으로 Term-Term Matrx를 생성해 주도록 합시다.
##TF-IDF 기준 Term-Term Matrix
tfidf_term_term_mat = cosine_similarity(tfidf_vector.T)
tfidf_term_term_mat = pd.DataFrame(tfidf_term_term_mat,
index=tfidf_vectorizer.vocabulary_,
columns=tfidf_vectorizer.vocabulary_)
tfidf_term_term_mat_100 = tfidf_term_term_mat[tfidf_term_term_mat.keys().isin(tfidf_vocab[:100])]
tfidf_term_term_mat_100 = tfidf_term_term_mat_100[tfidf_term_term_mat_100.columns.intersection(tfidf_vocab[:100])]
tfidf_term_term_mat_100
이제 TF-IDF를 기준으로 term-term matrix가 생성되었습니다. 이제 이를 네트워크 분석툴인 gephi에 적용시켜 분석을 진행해 보도록합시다. Gephi는 NetBeans 플랫폼에서 Java로 작성된 오픈 소스 네트워크 분석 및 시각화 소프트웨어 패키지로 다음 포스팅에서 자세하게 이어나가겠습니다. Gephi의 경우 아래에서 자신의 OS에 맞춰서 다운받을수 있습니다.
Gephi - The Open Graph Viz Platform
The Open Graph Viz Platform Gephi is the leading visualization and exploration software for all kinds of graphs and networks. Gephi is open-source and free. Runs on Windows, Mac OS X and Linux. Learn More on Gephi Platform » Support us! We are non-profit.
gephi.org
Gephi를 실행시키면 아래의 그림처럼 확인할 수 있는데, File -> Import Spreadsheet에서 위에서 생성한 term-term matrix를 적용시켜주었습니다.

해당 term-term matrix를 적용시키면 아래의 그림과 같이 노드와 엣지가 형성되는것을 확인할 수 있습니다.
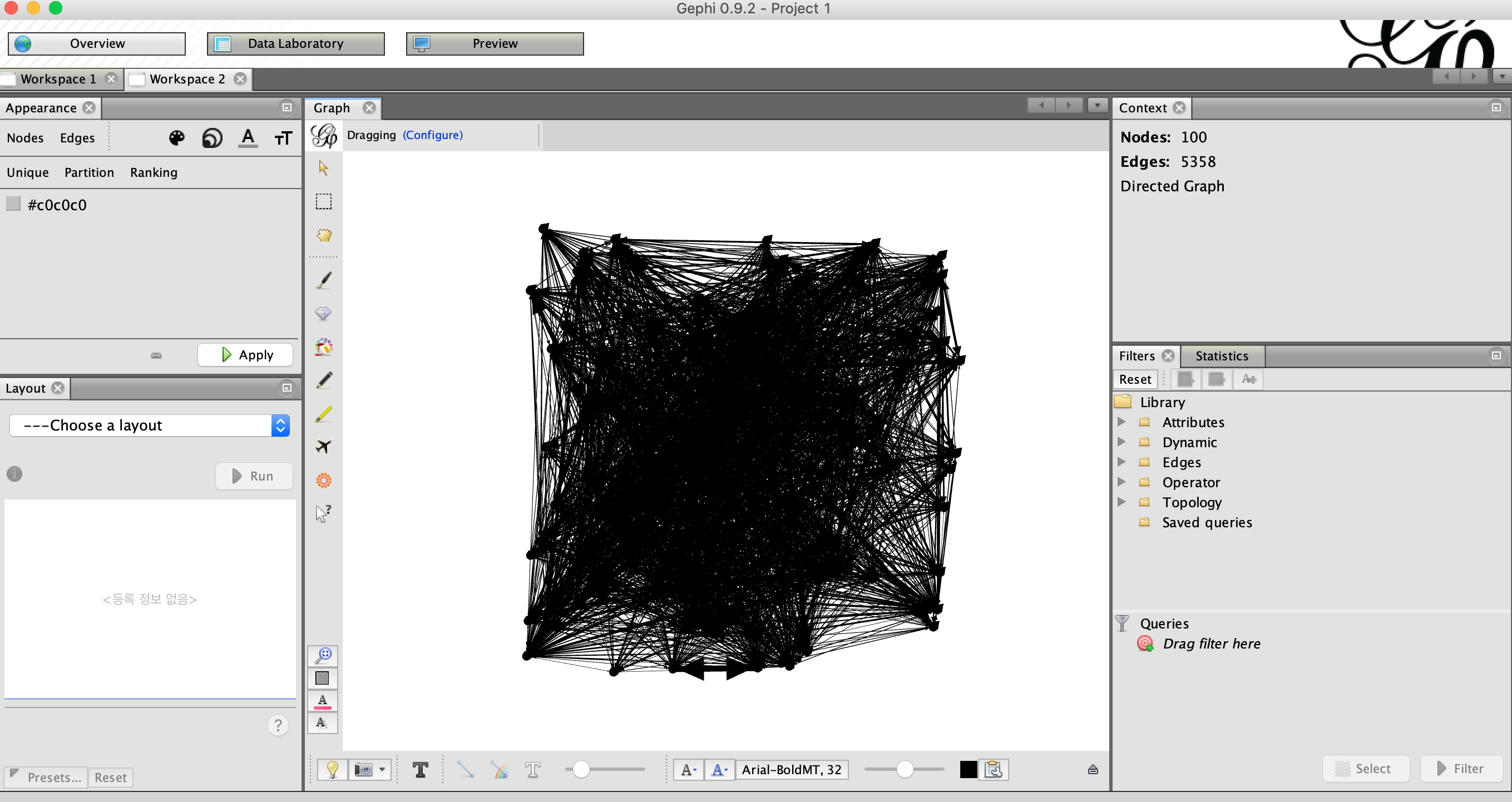
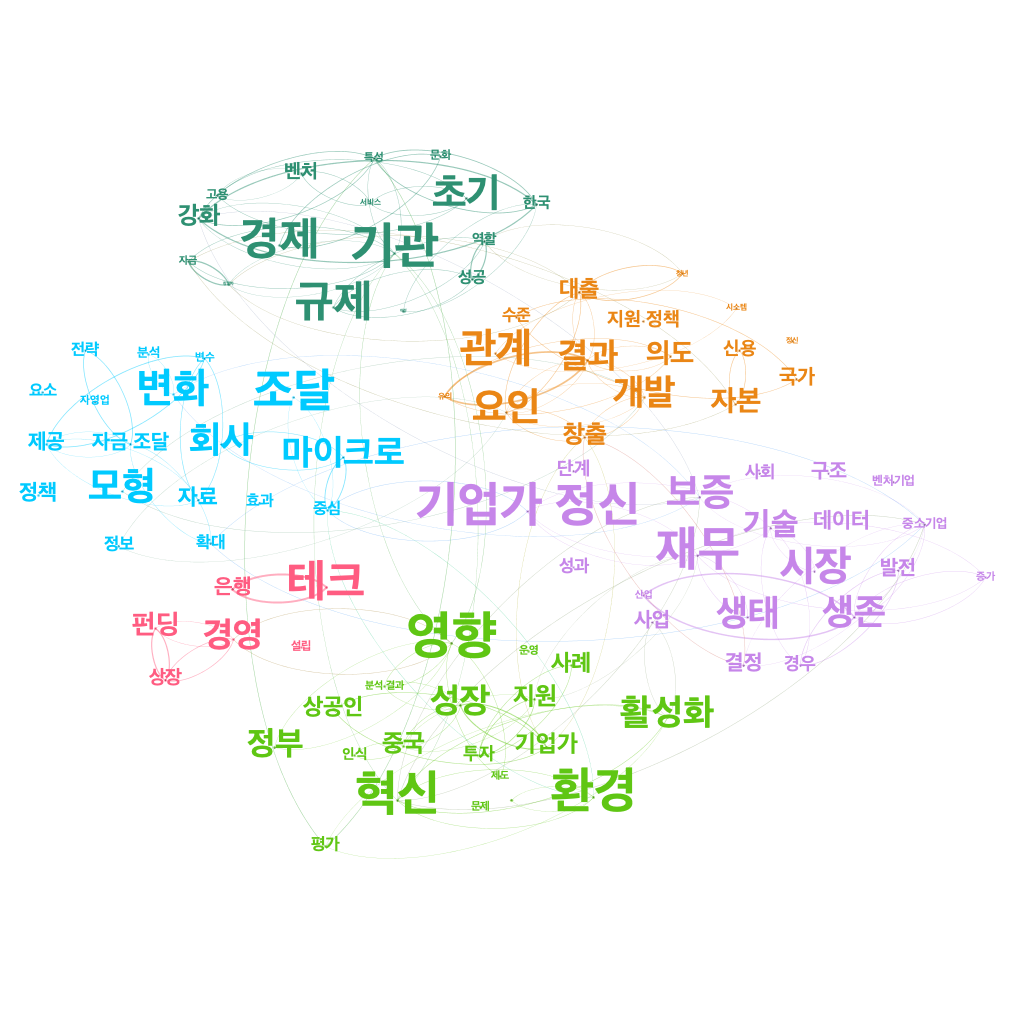
이후, modularity 알고리즘과 degree centrality를 통해 클러스터를 나누고 시각화를 진행시켜 보도록 하겠습니다. Modularity는 네트워크 또는 그래프의 구조를 측정하는 한 가지 방법으로써 네트워크를 클러스터로 분할하는 강도를 측정하도록 설계된 알고리즘입니다. 또한 modularity 네트워크에서 커뮤니티 구조를 감지하기 위한 최적화 방법에 활용할 수 있습니다. 또한 degree centrality는 위에서 설명한것과 같이 degree를 사용하여 중앙성을 파악합니다. 시각화를 진행해보면 아래 그림과 같이 확인 할 수 있습니다.

마지막으로 깔끔한 시각화를 진행하기위해 노드의 크기를 줄이고 엣지의 weight을 조정하여 아래와 같이 결과물을 도출할수있었습니다.
'자연어처리' 카테고리의 다른 글
| How to write a spelling corrector (0) | 2022.04.29 |
|---|---|
| SentiwordNet (0) | 2022.04.23 |
| 나이브 베이즈 분류기(Naive Bayes Classifier) (0) | 2022.04.20 |
| Dynamic Topic Modeling (0) | 2022.04.11 |
| 토픽모델링이란 (0) | 2022.03.03 |


