
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Enriching Word Vectors with Subword Information
- sensibleness
- 감성분석
- word2vec
- word representation
- topic modeling
- 구글클라우드플랫폼
- semantic network
- 임베딩
- 의미연결망
- 허깅페이스
- 동적토픽모델링
- hugging face
- Meena
- Min-Max 알고리즘
- QANet
- Holdout
- sbert
- GCP
- 사회연결망분석
- type-hint
- degree centrality
- Google Cloud Platform
- 분류모델평가
- dynamic topic modeling
- 토픽모델링
- 알파베타가지치기
- ROC-AUC Curve
- sequential data
- 머신러닝
- Today
- Total
Dev.log
SentiwordNet 본문
SentiwordNet
인터넷 공간이 대중화됨에 따라 SNS와 같은 온라인 공간내에 존재하는 감정 정보를 추출 및 활용함으로써 특정 대상에 대한 인식을 파악하려는 연구들이 이루어졌습니다. 이러한 연구를 진행하기 위해 주로 인터넷 게시판, SNS, 블로그 등에 올려진 텍스트를 분석하여 주제에 대한 감정을 인식하고 분석하려는 연구를 감정분석(sentiment analysis)이라 할 수 있습니다. 이러한 분석을위해서는 어떤 표현이 긍적인지 부정인지를 정리해놓은 사전이 필요하게 됩니다. 하지만 사람이 사용하는 수만은 단어들을 일일히 수작업으로 긍정인지 부정인지 판단해서 정리하기는 어려운 일입니다. 그래서 Esuli와 Sebastiani는 SentiWordNet을 만들게 되었습니다. SentiWordNet는 감성분석과 같은 연구를 진행하기 위한 한가지 수단으로 반지도학습 기법을 바탕으로 WordNet의 Synset에 감성스코어를 매긴 어휘사전입니다. 감성스코어는 긍정, 부정, 그리고 중립으로 구성되어지고 한 synset에 대해 긍정 + 부정 + 중립 = 1 이 됩니다. 만약 긍정 = 1이면 그 synset은 강렬하게 긍정적인 의미인것이고, 반대로 부정 = 1이면 강렬하게 부정적인 의미를 지니게 됩니다.
SentiwordNet을 통한 Kaggle 내 COVID-19 Tweets 감성 분석
이번에는 SentiwordNet을 통해 코로나19 트위터 텍스트데이터에 대해 감성분석을 진행해 보도록 하겠습니다. 데이터셋의 경우 Kaggle에서 제공하는 COVID19 Tweets을 활용하였으며 해당 데이터셋은 아래의 링크에서 다운로드 할수 있습니다.
COVID19 Tweets
Tweets with the hashtag #covid19
www.kaggle.com
먼저 SentiwordNet을 통한 감성분석에 들어가기 앞서 관련 패키지들을 임포트 해줍니다.
import pandas as pd
import numpy as np
from datetime import datetime
from glob import glob또한 영문 자연어 분석을 위한 NLTK 패키지와 SentiwordNet을 활용하기위한 패키지를 임포트 해줍니다.
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet as wn
from nltk.corpus import sentiwordnet as swn
from nltk.stem import PorterStemmer
lemmatizer = WordNetLemmatizer()데이터셋을 데이터프레임형태로 변환후 확인해보면 총 179108개의 row와 13개의 column으로 이루어져있으며 전체적인 구성은 아래와 같이 나타남을 확인 할 수 있습니다.
df = pd.read_csv('/Downloads/covid19_tweets.csv')
df.head(3)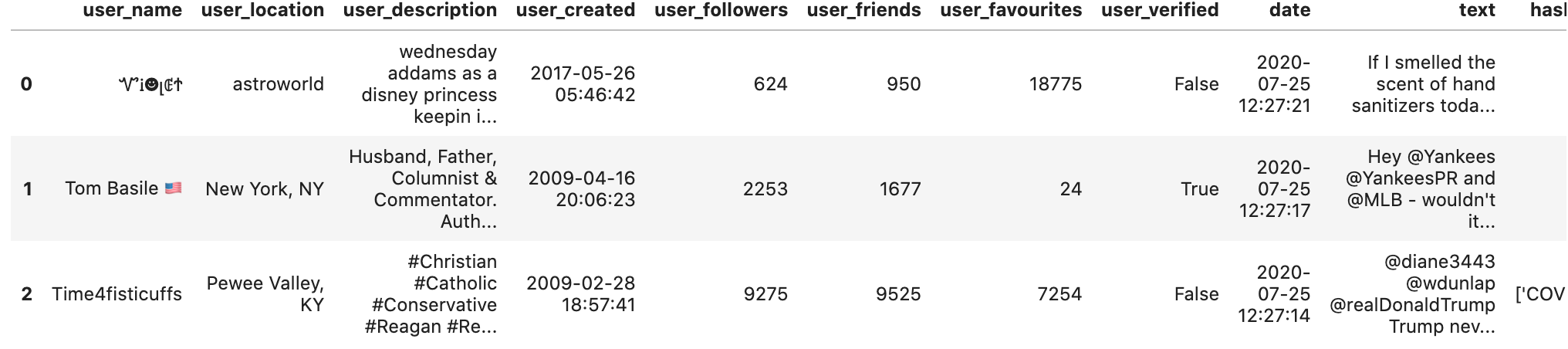
또한, 각 컬럼에는 유저의 이름, 정보, 생성된날짜, 본문, 본문이 생성된 날짜와 같은 정보들이 들어있는것을 확인 할 수있습니다. 이번 포스팅에서는 각 날짜별 COVID-19에 대한 감성분석을 진행하기위해 13개의 컬럼중 'date'과 'text'만을 활용하여 SentiwordNet을 통한 감성분석을 진행해보도록 하겠습니다.
Index(['user_name', 'user_location', 'user_description', 'user_created',
'user_followers', 'user_friends', 'user_favourites', 'user_verified',
'date', 'text', 'hashtags', 'source', 'is_retweet'],
dtype='object')
COVID-19의 트위터 데이터를 살펴보면 분석을 진행하기 위해 데이터를 정제하는 전처리과정을 거쳐야 합니다. 먼저 특수문자나 3글자이하의 경우 분석에 용이하지 않다 판단하여 제거해 주도록 하겠습니다. 또한 email형태의 단어와 전체 단어에 대해 소문자로 변환시켜주었습니다.
def data_cleansing(df):
delete_email = re.sub(r'\b[\w\+]+@[\w]+.[\w]+.[\w]+.[\w]+\b', ' ', df)
delete_number = re.sub(r'\b|\d+|\b', ' ',delete_email)
delete_non_word = re.sub(r'\b[\W]+\b', ' ', delete_number)
cleaning_result = ' '.join(delete_non_word.split())
return cleaning_result
df.loc[:, 'clean_text'] = df['text'].apply(data_cleansing)
# 특수 문자 제거
df['clean_text'] = df['clean_text'].str.replace("[^a-zA-Z]", " ")
# 길이가 3이하인 단어는 제거 (길이가 짧은 단어 제거)
df['clean_text'] = df['clean_text'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
# 전체 단어에 대한 소문자 변환
df['clean_text'] = df['clean_text'].apply(lambda x: x.lower())특정 문자들을 제거시켜준뒤 분석에 불필요한 불용어들에 대한 처리를 NLTK의 stopword와 추가적인 stopword를 통해 진행시켜주었습니다.
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = stopwords.words('english')
stop_words.extend(['ms','mr','http','www','co','html','goo_gl','blog','rt','https','bit','goo','gl','ly','com','nytimes','ow','new','york','times',
'news','also','even','still','much','day','could','nytime','washington','photo','section','\'s','inc','washpost',
'thing','something','percent','und','literature', 'may', 'paper', 'der','die','eine','von','however','elsevier',
'author','well','rights','reserve','_reserve','reserved','be','que','fur','das','den','auf','ein','des','would','latime','nyt',
'say','org','uk','eu','fb','do','govt','pic_twitter','pic','twitter','site','pm','website','twitt','net','ca',
'web','cc','lnkd','linkedin','away','soon','maybe','bn','pdf','et','al','wsj','report','bloomberg','tinyurl','From',',The'])
#정규영어x 불용어처리
non_eng_words = "ˆã?ªã,¢ãƒªã,‰,¹ã?«ã?•ã,ã,abis,ada,adek,ah,aja,ajan,ako,aku,akut,ampang,anak,apa,ape,atau,babit,baek,bagus,bahasekan,bahru,baik,bali,balik,bangun,bantu,banyak,baru,bayar,bb,bbm,beda,beli,berani,berisi,berteman,besok,betul,bgt,bhs,bikin,bila,bintang,bisa,blanje,bleh,blm,boleh,bontot,bos,brg,buat,bukan,cakap,camp,cinta,ckp,coba,cos,cuma,da,dah,dan,dari,dat,degil,deh,den,dengar,dgn,dgr,di,dia,dikit,diluar,doa,dong,duit,dulu,fyp,gag,gak,geisha,gewoon,gila,gimana,gitu,gk,gua,gue,guru,gw,hahaha,hari,haris,harus,hati,hujan,ingat,itu,iya,jadi,jagoin,jajan,jalan,jam,jd,jengok,jodoh,judulnya,juga,kacau,kakgue,kalau,kalo,kamu,kan,kangen,kasi,kasus,kat,kata,kau,kayy,ke,kekurusan,keliru,kerjaan,ketauan,kilat,kita,klo,kmu,knapa,kok,kol,kosong,krn,kuala,kurus,la,lagi,lain,lama,lamaan,lame,lemak,lerr,lge,lho,liat,liatin,libur,lulus,luna,lupa,mah,mahu,makan,mana,mao,masih,mau,mcm,melihat,mencintai,mengerti,menit,mereka,met,mga,milih,msh,mungkin,nabei,nabung,nak,naloka,nama,nana,nangis,nanti,nasi,ne,ngak,ngan,ngantuk,ngerti,ngga,ngn,ni,nih,nk,no,ntar,ntr,ny,nya,nye,orang,pagi,pakai,pake,pakwe,par,pas,pasir,pasti,pe,penting,per,pernah,pertemanan,pgi,pikir,pon,pulak,pulsa,pun,punya,racun,ramas,rase,rindu,rmh,rumah,sabar,sah,sakit,salah,sama,saman,sampe,sanggu,sangka,satu,saya,sebelum,seh,sekarang,selalu,semalam,semlm,semua,sendiri,seorang,sia,sih,skrg,smlm,smpi,suka,suroh,suruh,tak,tali,tangan,tapi,tau,taun,teman,tentu,terperap,terspam,tertipu,tetap,tidur,tlad,tolong,trs,trus,tuh,uang,uda,udah,udh,une,untuk,utk,waktu,ya,yaa,yah,yang,yazid,yg,yosie,yuk."
non_eng_words = non_eng_words.split(',')
stop_words.extend(non_eng_words)
#common word
smrt_com_words = "reuters,ap,jan,feb,mar,apr,may,jun,jul,aug,sep,oct,nov,dec,tech,news,index,mon,tue,wed,thu,fri,sat,'s,a,a's,able,about,above,according,accordingly,across,actually,after,afterwards,again,against,ain't,all,allow,allows,almost,alone,along,already,also,although,always,am,amid,among,amongst,an,and,another,any,anybody,anyhow,anyone,anything,anyway,anyways,anywhere,apart,appear,appreciate,appropriate,are,aren't,around,as,aside,ask,asking,associated,at,available,away,awfully,b,be,became,because,become,becomes,becoming,been,before,beforehand,behind,being,believe,below,beside,besides,best,better,between,beyond,both,brief,but,by,c,c'mon,c's,came,can,can't,cannot,cant,cause,causes,certain,certainly,changes,clearly,co,com,come,comes,concerning,consequently,consider,considering,contain,containing,contains,corresponding,could,couldn't,course,currently,d,definitely,described,despite,did,didn't,different,do,does,doesn't,doing,don't,done,down,downwards,during,e,each,edu,eg,e.g.,eight,either,else,elsewhere,enough,entirely,especially,et,etc,etc.,even,ever,every,everybody,everyone,everything,everywhere,ex,exactly,example,except,f,far,few,fifth,five,followed,following,follows,for,former,formerly,forth,four,from,further,furthermore,g,get,gets,getting,given,gives,go,goes,going,gone,got,gotten,greetings,h,had,hadn't,happens,hardly,has,hasn't,have,haven't,having,he,he's,hello,help,hence,her,here,here's,hereafter,hereby,herein,hereupon,hers,herself,hi,him,himself,his,hither,hopefully,how,howbeit,however,i,i'd,i'll,i'm,i've,ie,i.e.,if,ignored,immediate,in,inasmuch,inc,indeed,indicate,indicated,indicates,inner,insofar,instead,into,inward,is,isn't,it,it'd,it'll,it's,its,itself,j,just,k,keep,keeps,kept,know,knows,known,l,lately,later,latter,latterly,least,less,lest,let,let's,like,liked,likely,little,look,looking,looks,ltd,m,mainly,many,may,maybe,me,mean,meanwhile,merely,might,more,moreover,most,mostly,mr.,ms.,much,must,my,myself,n,namely,nd,near,nearly,necessary,need,needs,neither,never,nevertheless,new,next,nine,no,nobody,non,none,noone,nor,normally,not,nothing,novel,now,nowhere,o,obviously,of,off,often,oh,ok,okay,old,on,once,one,ones,only,onto,or,other,others,otherwise,ought,our,ours,ourselves,out,outside,over,overall,own,p,particular,particularly,per,perhaps,placed,please,plus,possible,presumably,probably,provides,q,que,quite,qv,r,rather,rd,re,really,reasonably,regarding,regardless,regards,relatively,respectively,right,s,said,same,saw,say,saying,says,second,secondly,see,seeing,seem,seemed,seeming,seems,seen,self,selves,sensible,sent,serious,seriously,seven,several,shall,she,should,shouldn't,since,six,so,some,somebody,somehow,someone,something,sometime,sometimes,somewhat,somewhere,soon,sorry,specified,specify,specifying,still,sub,such,sup,sure,t,t's,take,taken,tell,tends,th,than,thank,thanks,thanx,that,that's,thats,the,their,theirs,them,themselves,then,thence,there,there's,thereafter,thereby,therefore,therein,theres,thereupon,these,they,they'd,they'll,they're,they've,think,third,this,thorough,thoroughly,those,though,three,through,throughout,thru,thus,to,together,too,took,toward,towards,tried,tries,truly,try,trying,twice,two,u,un,under,unfortunately,unless,unlikely,until,unto,up,upon,us,use,used,useful,uses,using,usually,uucp,v,value,various,very,via,viz,vs,w,want,wants,was,wasn't,way,we,we'd,we'll,we're,we've,welcome,well,went,were,weren't,what,what's,whatever,when,whence,whenever,where,where's,whereafter,whereas,whereby,wherein,whereupon,wherever,whether,which,while,whither,who,who's,whoever,whole,whom,whose,why,will,willing,wish,with,within,without,won't,wonder,would,would,wouldn't,x,y,yes,yet,you,you'd,you'll,you're,you've,your,yours,yourself,yourselves,z,zero"
smrt_com_words = smrt_com_words.split(',')
stop_words.extend(smrt_com_words)이후 텍스트들에 대해 토크나이징을 진행시켜준뒤 위에서 생성된 불용어들에 대해 처리를 진행시켜줍시다.
tokenized_doc = df['clean_text'].apply(lambda x: x.split()) # 토큰화
tokenized_doc = tokenized_doc.apply(lambda x: [item for item in x if item not in stop_words])
이제 SentwordNet을 통해 감성분석을 진행해 주도록 합시다.
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet as wn
from nltk.corpus import sentiwordnet as swn
from nltk.stem import PorterStemmer
lemmatizer = WordNetLemmatizer()
def penn_to_wn(tag):
if tag.startswith('J'):
return wn.ADJ
elif tag.startswith('N'):
return wn.NOUN
elif tag.startswith('R'):
return wn.ADV
elif tag.startswith('V'):
return wn.VERB
return None
def get_sentiment(word,tag):
wn_tag = penn_to_wn(tag)
if wn_tag not in (wn.NOUN, wn.ADJ, wn.ADV):
return []
lemma = lemmatizer.lemmatize(word, pos=wn_tag)
if not lemma:
return []
synsets = wn.synsets(word, pos=wn_tag)
if not synsets:
return []
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
return [swn_synset.pos_score()-swn_synset.neg_score()]
def flatten(l):
flatList = []
for elem in l:
if type(elem) == list:
for e in elem:
flatList.append(e)
else:
flatList.append(elem)
return flatList
ps = PorterStemmer()
pdf = pdf.sort_values(by=['date'],ascending=True).reset_index(drop=True)
for i in range(len(pdf)):
pdf['date'][i] = pdf['date'][i][0:10]
scores=[np.sum(flatten([get_sentiment(x,y) for (x,y) in nltk.pos_tag(i)])) for i in pdf['tokenized_doc']]
'자연어처리' 카테고리의 다른 글
| 문서간 유사도: Jaccard Similarity & Cosine Similarity (0) | 2022.04.29 |
|---|---|
| How to write a spelling corrector (0) | 2022.04.29 |
| Semantic Network Analysis (0) | 2022.04.23 |
| 나이브 베이즈 분류기(Naive Bayes Classifier) (0) | 2022.04.20 |
| Dynamic Topic Modeling (0) | 2022.04.11 |

