
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- type-hint
- QANet
- semantic network
- 구글클라우드플랫폼
- 분류모델평가
- topic modeling
- 임베딩
- Holdout
- 사회연결망분석
- ROC-AUC Curve
- sequential data
- Min-Max 알고리즘
- sbert
- sensibleness
- 머신러닝
- degree centrality
- 의미연결망
- 동적토픽모델링
- GCP
- 알파베타가지치기
- dynamic topic modeling
- Enriching Word Vectors with Subword Information
- word2vec
- 감성분석
- 토픽모델링
- hugging face
- 허깅페이스
- Meena
- word representation
- Google Cloud Platform
- Today
- Total
Dev.log
Gensim의 Latent Dirichlet Allocation를 통한 분석 본문
Latent Direchlet Allocation(LDA)
토픽 모델링은 문서의 집합에서 핵심 토픽을 찾아내는 알고리즘을 의미합니다. 이는 검색 엔진, 고객 민원 시스템 등과 같이 문서의 주제를 알아내는 일이 중요한 곳에서 사용되기도 합니다. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)은 이러한 토픽 모델링의 대표적인 알고리즘으로 주어진 문서들에서 어떠한 주제를 찾는 확률모델이라고 할 수 있습니다. 예를 들어 아래와 같은 문서들이 존재한다고 가정해봅시다.
문서1 = [Quantum Mechanics, Higgs Particle, Maxwell's Equation, Theory of Relativity]
문서2 = [Shakespeare, Tolstoy, Faust, 1984]
문서1은 Quantun Mechanics, Maxwell's Equation과 같은 단어들이 있는것을 통해 문서1에 대한 토픽은 물리학과 관련되어 있음을 유추해 낼 수 있습니다. 또한 문서2는 Shakespeare, Tolstory와 같은 단어들을 통해 문서2의 메인 토픽의 경우 문학과 관련이 있음을 알 수 있습니다. 다시 아래의 그림을 살펴보겠습니다.
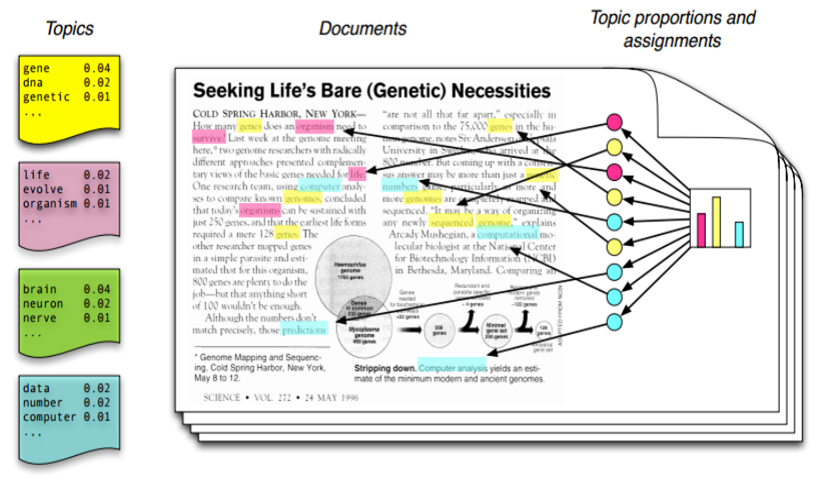
해당 그림에서 토픽은 총 4가지(노란색, 붉은색, 초록색, 파란색)으로 나타나며, 노란색토픽이 가장 많은 단어들을 내포하고 있음을 알 수 있습니다. 또한, 노란색 토픽의 경우 gene, dna, genetic과 같은 단어들로 이루어지고 각각 단어의 등장 확률은 0.04, 0.02, 0.01로 나타나는 것을 확인 할 수 있습니다. 이를 통해 해당 문서에서의 메인 토픽은 노란색 토픽이며, 노란색 토픽은 유전자에 관한 토픽이다 라고 유추할 수 있습니다.
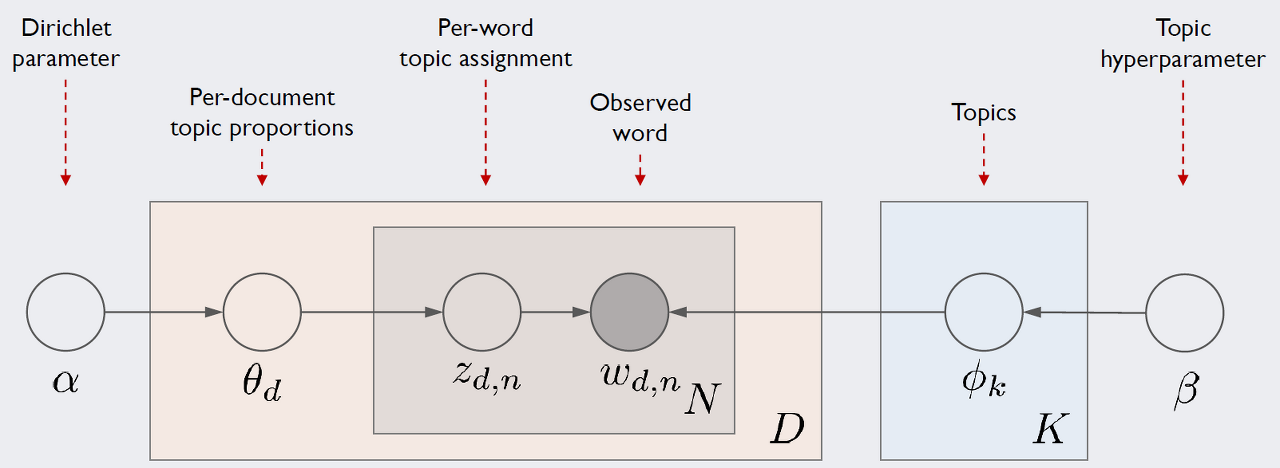
LDA가 가정하는 문서 생성과정은 다음과 같습니다. 먼저 D는 말뭉치 전체의 문서 갯수, K는 전체 토픽의 수, N은 d번째 문서의 단어 수를 의미합니다. 네모칸의 경우 해당 횟수만큼 반복하라는 의미이며, 동그라미는 변수를 의미합니다. 여기서 우리가 관찰 가능한 변수는 d번째 문서에서 n 번째 단어 w_d,n 이 유일합니다. 그래서 하이퍼파리미터인 α와 β를 제외한 모든 잠재 변수를 추정해야 합니다.
Gensim의 coherence score(c_v)를 통한 Latent Direchlet Allocation(LDA) 토픽 평가
Coherence Score는 주제에 대한 일관성 점수라고 표현할 수 있을것 같습니다. 실제로 사람이 해석하기 적합한 평가 척도를 만들기위해 제시된 몇가지 척도중 D Newman에 의해 2010년에 제시되었습니다. Newman의 연구팀은 뉴스데이터로 부터 토픽모델링을 실시하고 결과로 도출된 토픽들이 유의미한지를 수작업을 통해 점수를 측정하였습니다. 그리고 이렇게 매겨진 점수와 가장 유사한 결과를 낼 수 있는 척도를 도출 하였습니다.
c_v는 슬라이딩 윈도우, 상위 단어의 1세트 분할 및 정규화된 포인트별 상호 정보(NPMI) 및 코사인 유사도를 사용하는 간접 확인 측정을 기반으로 합니다. 이 일관성 측정은 슬라이딩 윈도우와 윈도우 크기 110을 사용하여 주어진 단어에 대한 동시 발생 횟수를 검색합니다. 횟수는 다른 모든 상위 단어에 대한 모든 상위 단어의 NPMI를 계산하는 데 사용되므로 결과적으로 벡터 세트가 생성됩니다. 상위 단어의 1세트 분할은 모든 상위 단어 벡터와 모든 상위 단어 벡터의 합 사이의 유사도를 계산하며 유사도 측정으로 코사인이 사용됩니다. 일관성은 이러한 유사성의 산술 평균입니다.

Latent Direchlet Allocation(LDA) 를 통한 Snapchat review 분석
데이터 셋의 경우 캐글(Kaggle)의 데이터셋중 하나인 10K Snapchat Review데이터를 사용하였으며, 해당 데이터셋은 아래의 링크에서 다운로드 받으실 수 있습니다.
10k Snapchat Reviews
A table with 10k App Store reviews for the Snapchat app
www.kaggle.com
LDA 분석에 들어가기 앞써 필요한 패키지들을 import 해 주었습니다.
import logging
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import gensim
from gensim.models import CoherenceModel
from gensim.models.coherencemodel import CoherenceModel
import gensim.corpora as corpora
import pyLDAvis
import pyLDAvis.gensim_models
import spacy
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizerLemmatizer의 경우 NLTK에서 제공해주는 WordNetLemmatizer를 사용하였습니다.
lemmatizer = WordNetLemmatizer()
nlp = spacy.load('en_core_web_sm')먼저 데이터의 형태를 확인해 주었습니다.
df.head(3)
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 9560 entries, 0 to 9559
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 userName 9560 non-null object
1 rating 9560 non-null int64
2 review 9560 non-null object
3 isEdited 9560 non-null bool
4 date 9560 non-null object
5 title 9560 non-null object
dtypes: bool(1), int64(1), object(4)
memory usage: 457.5+ KB주어진 데이터는 총 9560개의 row값으로 구성되었으며, userName, rating, review, isEdited, date, tile로 총 6개의 column으로 구성되었으며 각 컬럼마다 null값은 존재하지 않는것을 확인 할 수있습니다. 이제 데이터를 전처리하기위한 함수들을 구성해 주었습니다. 대문자의 경우 소문자로 변경해 주었으며, 길이가 3글자 미만인 단어들은 의미가 없다 판단하여 제외시켜주었습니다. 그외에도 NLTK를 통한 불용어처리, 사용자 지정 불용어처리를 진행해 주었습니다.
def DataFrame(data):
return data[['title','review','date']]
def preprocessing(data):
data['title'] = data['title'].astype('str')
data['review'] = data['review'].astype('str')
data["contents"] = data.apply(lambda x: x['title'] + "\n" + x['review'], axis=1) #title + abstract
data['contents'] = data['contents'].str.replace("[^a-zA-Z]", " ")
data['contents'] = data['contents'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
data['contents'] = data['contents'].apply(lambda x: x.lower())
return data
def stopword(data):
stop_words = stopwords.words('english')
non_eng_words = "ˆã?ªã,¢ãƒªã,‰,¹ã?«ã?•ã,ã,abis,ada,adek,ah,aja,ajan,ako,aku,akut,ampang,anak,apa,ape,atau,babit,baek,bagus,bahasekan,bahru,baik,bali,balik,bangun,bantu,banyak,baru,bayar,bb,bbm,beda,beli,berani,berisi,berteman,besok,betul,bgt,bhs,bikin,bila,bintang,bisa,blanje,bleh,blm,boleh,bontot,bos,brg,buat,bukan,cakap,camp,cinta,ckp,coba,cos,cuma,da,dah,dan,dari,dat,degil,deh,den,dengar,dgn,dgr,di,dia,dikit,diluar,doa,dong,duit,dulu,fyp,gag,gak,geisha,gewoon,gila,gimana,gitu,gk,gua,gue,guru,gw,hahaha,hari,haris,harus,hati,hujan,ingat,itu,iya,jadi,jagoin,jajan,jalan,jam,jd,jengok,jodoh,judulnya,juga,kacau,kakgue,kalau,kalo,kamu,kan,kangen,kasi,kasus,kat,kata,kau,kayy,ke,kekurusan,keliru,kerjaan,ketauan,kilat,kita,klo,kmu,knapa,kok,kol,kosong,krn,kuala,kurus,la,lagi,lain,lama,lamaan,lame,lemak,lerr,lge,lho,liat,liatin,libur,lulus,luna,lupa,mah,mahu,makan,mana,mao,masih,mau,mcm,melihat,mencintai,mengerti,menit,mereka,met,mga,milih,msh,mungkin,nabei,nabung,nak,naloka,nama,nana,nangis,nanti,nasi,ne,ngak,ngan,ngantuk,ngerti,ngga,ngn,ni,nih,nk,no,ntar,ntr,ny,nya,nye,orang,pagi,pakai,pake,pakwe,par,pas,pasir,pasti,pe,penting,per,pernah,pertemanan,pgi,pikir,pon,pulak,pulsa,pun,punya,racun,ramas,rase,rindu,rmh,rumah,sabar,sah,sakit,salah,sama,saman,sampe,sanggu,sangka,satu,saya,sebelum,seh,sekarang,selalu,semalam,semlm,semua,sendiri,seorang,sia,sih,skrg,smlm,smpi,suka,suroh,suruh,tak,tali,tangan,tapi,tau,taun,teman,tentu,terperap,terspam,tertipu,tetap,tidur,tlad,tolong,trs,trus,tuh,uang,uda,udah,udh,une,untuk,utk,waktu,ya,yaa,yah,yang,yazid,yg,yosie,yuk."
non_eng_words = non_eng_words.split(',')
smrt_com_words = "reuters,ap,jan,feb,mar,apr,may,jun,jul,aug,sep,oct,nov,dec,tech,news,index,mon,tue,wed,thu,fri,sat,'s,a,a's,able,about,above,according,accordingly,across,actually,after,afterwards,again,against,ain't,all,allow,allows,almost,alone,along,already,also,although,always,am,amid,among,amongst,an,and,another,any,anybody,anyhow,anyone,anything,anyway,anyways,anywhere,apart,appear,appreciate,appropriate,are,aren't,around,as,aside,ask,asking,associated,at,available,away,awfully,b,be,became,because,become,becomes,becoming,been,before,beforehand,behind,being,believe,below,beside,besides,best,better,between,beyond,both,brief,but,by,c,c'mon,c's,came,can,can't,cannot,cant,cause,causes,certain,certainly,changes,clearly,co,com,come,comes,concerning,consequently,consider,considering,contain,containing,contains,corresponding,could,couldn't,course,currently,d,definitely,described,despite,did,didn't,different,do,does,doesn't,doing,don't,done,down,downwards,during,e,each,edu,eg,e.g.,eight,either,else,elsewhere,enough,entirely,especially,et,etc,etc.,even,ever,every,everybody,everyone,everything,everywhere,ex,exactly,example,except,f,far,few,fifth,five,followed,following,follows,for,former,formerly,forth,four,from,further,furthermore,g,get,gets,getting,given,gives,go,goes,going,gone,got,gotten,greetings,h,had,hadn't,happens,hardly,has,hasn't,have,haven't,having,he,he's,hello,help,hence,her,here,here's,hereafter,hereby,herein,hereupon,hers,herself,hi,him,himself,his,hither,hopefully,how,howbeit,however,i,i'd,i'll,i'm,i've,ie,i.e.,if,ignored,immediate,in,inasmuch,inc,indeed,indicate,indicated,indicates,inner,insofar,instead,into,inward,is,isn't,it,it'd,it'll,it's,its,itself,j,just,k,keep,keeps,kept,know,knows,known,l,lately,later,latter,latterly,least,less,lest,let,let's,like,liked,likely,little,look,looking,looks,ltd,m,mainly,many,may,maybe,me,mean,meanwhile,merely,might,more,moreover,most,mostly,mr.,ms.,much,must,my,myself,n,namely,nd,near,nearly,necessary,need,needs,neither,never,nevertheless,new,next,nine,no,nobody,non,none,noone,nor,normally,not,nothing,novel,now,nowhere,o,obviously,of,off,often,oh,ok,okay,old,on,once,one,ones,only,onto,or,other,others,otherwise,ought,our,ours,ourselves,out,outside,over,overall,own,p,particular,particularly,per,perhaps,placed,please,plus,possible,presumably,probably,provides,q,que,quite,qv,r,rather,rd,re,really,reasonably,regarding,regardless,regards,relatively,respectively,right,s,said,same,saw,say,saying,says,second,secondly,see,seeing,seem,seemed,seeming,seems,seen,self,selves,sensible,sent,serious,seriously,seven,several,shall,she,should,shouldn't,since,six,so,some,somebody,somehow,someone,something,sometime,sometimes,somewhat,somewhere,soon,sorry,specified,specify,specifying,still,sub,such,sup,sure,t,t's,take,taken,tell,tends,th,than,thank,thanks,thanx,that,that's,thats,the,their,theirs,them,themselves,then,thence,there,there's,thereafter,thereby,therefore,therein,theres,thereupon,these,they,they'd,they'll,they're,they've,think,third,this,thorough,thoroughly,those,though,three,through,throughout,thru,thus,to,together,too,took,toward,towards,tried,tries,truly,try,trying,twice,two,u,un,under,unfortunately,unless,unlikely,until,unto,up,upon,us,use,used,useful,uses,using,usually,uucp,v,value,various,very,via,viz,vs,w,want,wants,was,wasn't,way,we,we'd,we'll,we're,we've,welcome,well,went,were,weren't,what,what's,whatever,when,whence,whenever,where,where's,whereafter,whereas,whereby,wherein,whereupon,wherever,whether,which,while,whither,who,who's,whoever,whole,whom,whose,why,will,willing,wish,with,within,without,won't,wonder,would,would,wouldn't,x,y,yes,yet,you,you'd,you'll,you're,you've,your,yours,yourself,yourselves,z,zero"
smrt_com_words = smrt_com_words.split(',')
stop_words.extend(non_eng_words)
stop_words.extend(smrt_com_words)
stop_words.extend(['ms','mr','http','www','co','html','goo_gl','blog','rt','https','bit','goo','gl','ly',
'com','nytimes','ow','new','york','times', 'news','also','even','still','much','day','could',
'nytime','washington','photo','section','\'s','inc','washpost', 'thing','something','percent','und',
'literature', 'may', 'paper', 'der','die','eine','von','however','elsevier', 'author','well','rights',
'reserve','_reserve','reserved','be','que','fur','das','den','auf','ein','des','would','latime','nyt',
'say','org','uk','eu','fb','do','govt','pic_twitter','pic','twitter','site','pm','website','twitt',
'net','ca','web','cc','lnkd','linkedin','away','soon','maybe','bn','pdf','et','al','wsj','report',
'bloomberg','tinyurl','From',',The','snap','chat','snapchat'
])
data['tokens'] = data['contents'].apply(lambda x: x.split())
data['tokens'] = data['tokens'].apply(lambda x: [item for item in x if item not in stop_words])
return data
def lemmatization(texts, allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV']):
texts_out = []
for sent in texts:
doc = nlp(" ".join(sent))
texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])
return texts_out
def preprocessed_data(data):
Ddata = DataFrame(data)
Pdata = preprocessing(Ddata)
Sdata = stopword(Pdata)
Sdata['lemmatized'] = lemmatization(Sdata['tokens'], allowed_postags=['NOUN', 'ADJ', 'VERB', 'ADV'])
return Sdata이제 토픽모델링의 coehrence score를 계산해주는 함수를 구성해 주었습니다.
def compute_coherence_values(dictionary, corpus, texts, limit, start=2, step=3):
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=id2word, num_topics=num_topics)
model_list.append(model)
coherencemodel = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
def find_optimal_number_of_topics(dictionary, corpus, processed_data):
limit = 30;
start = 2;
step = 6;
model_list, coherence_values = compute_coherence_values(dictionary=dictionary, corpus=corpus, texts=processed_data, start=start, limit=limit, step=step)
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()Coherence score를 통해 최적의 토픽을 찾아본결과 토픽의 갯수가 9개로 구성되었을시 토픽의 분포 및 토픽내 단어들이 해당 토픽을 가장 잘 설명해 주는것으로 확인되었습니다.
data = preprocessed_data(df)
id2word = corpora.Dictionary(data['lemmatized'])
token = data['lemmatized']
text = data['contents']
corpus = [id2word.doc2bow(text) for text in (token)]
processed_data = token
dictionary = id2word
dictionary.filter_extremes(no_below=10, no_above=0.05)
corpus = [dictionary.doc2bow(text) for text in processed_data]
#print('Number of unique tokens: %d' % len(dictionary))
#print('Number of documents: %d' % len(corpus))
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
find_optimal_number_of_topics(dictionary, corpus, processed_data)
토픽수 k를 9로 지정해 주었으며 LDA시각화를 위해 pyLDAvis를 통해 시각화를 진행시켜 주었습니다.
lda_model = gensim.models.LdaMulticore(corpus = corpus,
id2word = id2word,
num_topics = 9,
random_state = 100,
chunksize = 100,
passes = 10,
alpha = 0.01,
eta = 0.9)
vis = pyLDAvis.gensim_models.prepare(lda_model, corpus, id2word)
pyLDAvis.enable_notebook()
pyLDAvis.display(vis)

'자연어처리' 카테고리의 다른 글
| Hugging Face의 Sentence Transformer (0) | 2022.06.11 |
|---|---|
| Graph centrality를 통한 금융 자연어 데이터 분석 (0) | 2022.06.10 |
| Sentence BERT (0) | 2022.05.11 |
| Bag of Words (0) | 2022.05.10 |
| 문서간 유사도: Jaccard Similarity & Cosine Similarity (0) | 2022.04.29 |