
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 감성분석
- sensibleness
- 머신러닝
- semantic network
- Google Cloud Platform
- 분류모델평가
- Holdout
- 허깅페이스
- sbert
- 사회연결망분석
- dynamic topic modeling
- QANet
- GCP
- 동적토픽모델링
- topic modeling
- ROC-AUC Curve
- 구글클라우드플랫폼
- type-hint
- 알파베타가지치기
- Meena
- 임베딩
- degree centrality
- Enriching Word Vectors with Subword Information
- sequential data
- word representation
- 토픽모델링
- hugging face
- Min-Max 알고리즘
- word2vec
- 의미연결망
- Today
- Total
Dev.log
Confusion matrix 본문
모델에 대한 성능 평가를 위해서 일반적으로는 정확도(accuracy)라는 기준을 주로 사용하는데, 정확도만을 이용하여 모델을 평가하기에는 충분하지 않을 수 있습니다. 예를 들어 이번 코로나 감염에 대해 머신러닝을 통해서 분류한다고 가정해 봅시다. 코로나의 발병률은 일반적으로 극히 낮기에 ‘코로나에 걸리지 않았다’라고 학습하게 되면 모델의 예측 정확도가 거의 100%에 수렴할 수 있습니다. 하지만 이 모델에서는 코로나에 진짜 걸렸는지를 잘 판별하고 싶었던 것이지, 코로나에 안 걸렸다는 사실을 판별하고 싶었던 것은 아닐 것입니다. 이러한 상황을 불균형 데이터(skewed class)문제라고 합니다.
Confusion matrix
정확도만으로는 모델의 성능평가가 힘든데, 이때 주로 confusion matrix를 활용하기도 합니다. Confusion matrix는 데이터의 예측 범주와 실제 범주를 교차 표의 형태로 정리한 행렬을 의미하는데, 가설 검정시에 1종 오류(type 1 error)와 2종 오류(type 2 error)의 개념을 분류하기 위해 주로 언급되기도 합니다.
머신러닝에서도 confusion matrix는 예측데이터와 실제 데이터를 비교해서 분류가 얼마나 잘 되었는지를 보는 방법으로, 비유하자면 기계가 푼 시험지를 정답을 두고 채점하는 방식이기 때문에 지도학습(supervised learning)에서 쓰이는 개념이라고 할 수 있습니다. Confusion matrix는 ‘코로나에 걸렸는가’라는 명제를 가지고 2진법(binary) 기계학습을 한다고 가정하자. 2진법은 ‘Yes or No’이므로, 머신러닝을 통해 분류를 하면 코로나에 걸렸다고 예측한 긍정(positive) 데이터와 코로나에 걸리지 않았다고 예측한 부정(negative) 데이터 얻을 수 있을 것입니다. 이 데이터들을 참인가(True) 거짓인가(False)로 판별하여 2x2의 모형을 만드는 것이 바로 Confusion matrix이다.
따라서 Confusion matrix에는 총 4개의 분류기준(parameters)이 있습니다. 참인데 참이라고 분류한 경우(true positive, TP), 거짓인데 참으로 분류한 경우(false positive, FP), 거짓인데 거짓으로 분류한 경우(true negative, TN) 및 참인데 거짓으로 분류한 경우(false negative, FN)로 나누어집니다. 이를 보기쉽게 표로 표현하면 아래와 같습니다.
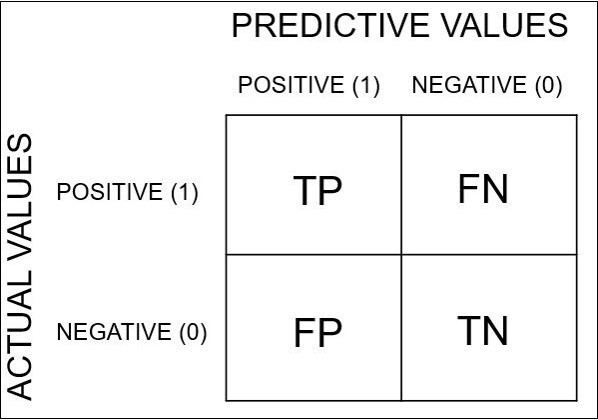
정확도(Accuracy)
정확도는 모델의 성능을 가장 직관적으로 보여주는 지표로써 실제 분류 범주를 올바르게 예측한 비율을 의미합니다. 전체 데이터인 TP, FN, FP, TN 중 기계가 정확히 분류해낸 TP와 TN이 전체에서 얼마나 비율을 차지하는지를 보고 모델의
정확도를 평가하는 척도입니다.
정밀도(Precision)
정밀도는 참이라고 예측된 데이터인 TP와 FP 중에서 실제로 참인 데이터인 TP의 비율을 측정하는 방법입니다. 즉, 1종 오류(실제로는 틀렸지만 옳다고 판단하는 경우)와의 비율을 통해 모델의 신뢰도를 측정하는 방법이라고 할 수 있습니다.
재현도(Recall)
재현도는 정밀도와 비교되는 척도이며, 실제로 참인 TP와 FN 데이터 중에서 기계가 올바르게 예측한 TP의 비율을 측정하는 방법입니다. 2종 오류(실제로는 맞지만 틀렸다고 하는 경우)와의 비율을 통해 모델의 실용성을 측정하는 방법으로 민감도(sensitivity)라고 불리기도 합니다.
F-1 Score
F-1 score는 정밀도와 재현도의 조화평균(harmonic mean)으로 정밀도와 재현도의 밸런스를 고려하여 모델을 평가하는 방법입니다. 수식으로 표현하면 아래와 같이 나타납니다.
$$F1=2*precision*recall/(precision+recall)$$
'머신러닝과 딥러닝' 카테고리의 다른 글
| Deep Neural Network (0) | 2022.05.31 |
|---|---|
| 교차검증 (0) | 2022.03.02 |
| 랜덤포레스트(Random Forest) (0) | 2022.02.19 |
| 머신러닝(Machine Learning; 기계학습) 이란? (0) | 2022.02.18 |
| CNN(Convolutional neural network)의 배경 (0) | 2022.02.17 |


