
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Holdout
- 허깅페이스
- type-hint
- 구글클라우드플랫폼
- 동적토픽모델링
- Meena
- sbert
- Min-Max 알고리즘
- degree centrality
- hugging face
- 의미연결망
- 임베딩
- 알파베타가지치기
- Google Cloud Platform
- 분류모델평가
- 토픽모델링
- dynamic topic modeling
- 사회연결망분석
- sensibleness
- QANet
- GCP
- word representation
- semantic network
- topic modeling
- sequential data
- 감성분석
- ROC-AUC Curve
- word2vec
- 머신러닝
- Enriching Word Vectors with Subword Information
- Today
- Total
Dev.log
교차검증 본문
모델을 설계를 하다보면 각 모델별로 필요한 파라미터(Parameter.매개변수)들이 존재합니다. 파라미터란 모델 내에서 결정되는 평균, 표준편차, 선형회귀 계수와 같은 변수들을 의미합니다. 이러한 변수들의 개념을 생각해본다면, 이들은 사용자가 지정하는 것이 아니라 데이터에 따라서 자동으로 결정되는 것임을 알 수 있습니다. 또한 이러한 파라미터가 어떻게 결정되는가에 따라 모델의 성능 및 동작이 크게 달라지기도 합니다. 하이퍼파라미터(hyperparameter)는 사용자가 임의로 예상하거나 목표하는 파라미터 값을 주로 의미하며, 신경망의 학습 (learning rate), 서포트 벡터 머신(SVM)의 C값, KNN에서의 K값 등이 이에 해당됩니다.
오버피팅(overfitting)
오버피팅(overfitting)이란 기계학습 모델이 기존 테스트 데이터에 너무 과대 적합되어서 다른 데이터로 모델을 사용하면 모델이 새로운 데이터에 대해 판별을 못하는 현상을 의미합니다. 즉, 모델이 기존의 학습데이터에 너무 맞추어져 있어서 새로운 데이터에는 적합하지 않다는 뜻입니다. 오버피팅을 해소하려면 모델을 단순화하거나, 데이터의 질을 높이거나, 모델에 더 많은 제약을 가하는 방법들이 있습니다.
언더피팅(overfitting)
반대로 언더피팅(underfitting)은 모델이 너무 과소적합되어 새로운 데이터에 맞지 않는 것을 말한다. 즉 모델이 너무 단순해서 현실을 못 따라가는 경우를 흔히 말하는데, 예를 들어 경제분야의 거시적 지표는 너무 다양한 변수들을 포함하고 있어서 모델이 예측하기 힘들 수도 있다. 언더피팅을 해소하려면 모델을 복잡화하거나, 데이터의 양을 늘리거나, 모델의 제약을 없애는 방법들이 존재합니다.
머신러닝에 투입되는 데이터는 트레이닝 데이터(training data)와 테스트 데이터(test data) 2가지로 분류된다. 예를들어 데이터의 8할을 트레이닝 데이터로 설정하여 학습을 진행하고 2할을 테스트 데이터로 설정하여 학습모델에 적용해보면서 모델의 성능을 확인하게 됩니다. 만약 트레이닝 데이터로 얻은 모델이 테스트 데이터를 학습시켜도 좋은 성능을 보여준다면, 다른 데이터를 대입시켜도 좋은 성능을 낼 수 있다고 예측하는 것입니다 2원적 분류법에서 파라미터는 바로 이 테스트 데이터셋에서 결정됩니다.
하지만 테스트 데이터셋을 통해 파라미터를 결정하는 것이 옳은가에 대한 의문점이 있습니다. 실제 테스트 데이터셋을 여러번 재사용하면 예측이 현실과는 다르게 너무 낙관적으로 흘러가는 경우가 발생하여 오버피팅이 발생할 가능성이 존재합니다. 이러한 부분을 해결하기위해 교차검증을 주로 사용하며 교차검증의 종류는 아래와 같습니다.
Holdout Cross Validation
홀드아웃 주어진 데이터를 랜덤하게 트레이닝 데이터와 테스트 데이터로 나눈 후 트레이닝 데이터를 모델 훈련에 사용하고 테스트 데이터를 모델 평가에 사용하는 교차검증 방법 중 한 가지 입니다. 홀드아웃 교차검증은 훈련 및 검증을 한 번만 시행하여 계산 시간이 적게 소요되는 장점이 존재하는 반면, 검증방법이 간단하기에 파라미터 튜닝 작업을 반복하다 보면 모델이 테스트 데이터에 대해 오버피팅이 발생할 가능성이 높아진다는 단점이 존재한다. 홀드아웃 검증 방법의 과정은 다음과 같습니다.
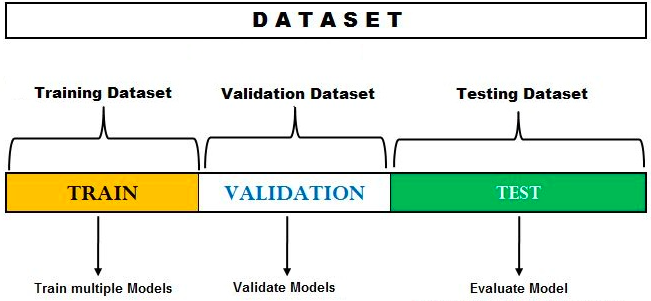
| 1. 데이터를 두 개의 트레이닝 데이터와 테스트 데이터로 분리시켜 준다. 일반적으로 트레이닝 데이터와 테스트 데이터의 비율을 7:3으로 지정시켜준다. 2. 트레이닝 데이터를 사용하여 적합한 하이퍼파라미터와 학습모델을 선정하여준다. 3. 모델을 사용하여 테스트 데이터의 클레스 라벨을 예측한다. 또한 일반화 성능 추정을 위해 예측 및 결과의 라벨을 서로 비교한다. 4. 모든 데이터셋을 최종 모델 학습에 수행한다. |
K-Fold Cross Validation

K-fold는 데이터셋을 k개의 그룹으로 나눠 사용하는 교차 검증입니다. 분리된 k개의 그룹 중 한 그룹만 k-1을 학습데이터로 사용 하여 k개의 모델을 추정하는 방식으로써, k값이 10인 10-fold 방식의 경우 전체 자료를 10등분 한 후에 9등분을 학습에 사용하고 나머지 한 등분을 평가에 사용 합니다. 그리고 이 과정을 10번 반복한 후, 그 평균을 내어 각 학습모델을 평가하는 기법입니다. K-fold의 교차검증은 다음과 같이 이루어 집니다 :
|
LOOCV(Leave-one-out Cross-validation)

LOOCV은 leave-p-out 교차검증에서 p값이 1인 경우를 의미합니다. Leave-p-out 교차검증은 전체 데이터 중에서 총 p개의 샘플을 선정 후 p를 모델검증에 사용합니다. 하지만 leave-p-out 교차검증은 데이터셋의 경우의 수가 매우 크므로 계산 시간이 오래 걸린다는 단점이 존재합니다. 따라서 leave-p-out validation을 사용하면 p의 값을 1로 선정하므로 leave-p-out 교차검증에 비해 계산에 소요되는 시간이 줄어들며 검증에 사용되는 테스트셋의 수가 적기 때문에 훈련에 사용되는 데이터의 개수가 늘어나며, 검증에 사용되는 데이터인 p가 1이기 때문에 나머지 데이터들을 모델 훈련에 사용 가능하다는 장점이 존재합니다.
'머신러닝과 딥러닝' 카테고리의 다른 글
| Transfomer를 통한 시계열 데이터 예측 (5) | 2022.06.12 |
|---|---|
| Deep Neural Network (0) | 2022.05.31 |
| Confusion matrix (0) | 2022.02.21 |
| 랜덤포레스트(Random Forest) (0) | 2022.02.19 |
| 머신러닝(Machine Learning; 기계학습) 이란? (0) | 2022.02.18 |

