
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 토픽모델링
- sbert
- semantic network
- sensibleness
- dynamic topic modeling
- 임베딩
- degree centrality
- 의미연결망
- Min-Max 알고리즘
- 감성분석
- Holdout
- topic modeling
- 구글클라우드플랫폼
- Google Cloud Platform
- ROC-AUC Curve
- GCP
- type-hint
- QANet
- 분류모델평가
- sequential data
- 알파베타가지치기
- 머신러닝
- 허깅페이스
- hugging face
- Enriching Word Vectors with Subword Information
- word2vec
- 동적토픽모델링
- 사회연결망분석
- Meena
- word representation
- Today
- Total
Dev.log
Deep Neural Network 본문
Deep neural network
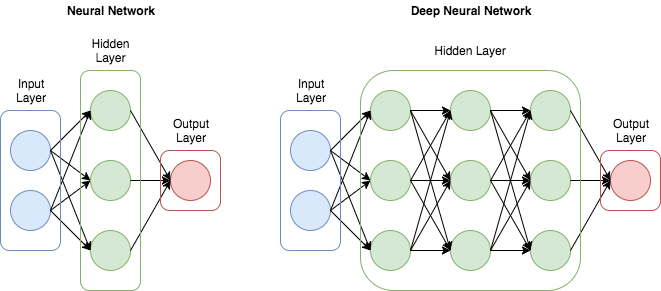
Deep neural networks는 인풋 레이어와 아웃풋 레이어 사이에 여러개의 레이어가있는 artificial neural network로 뉴럴넷 모델의 hidden layer를 많이 늘려서 학습의 결과를 향상시키는 방법을 의미합니다. 이러한 deep neural network를 확률분포함수라 표현을 하게 되면, deep neural network의 weight parameter는 이러한 확률 분포함수를 정의하는 파라미터라고 할 수 있습니다. 우리는 이러한 확률분포 함수를 가지고 세상에 존재하는 미지의 확률분포를 근사하고자 하는 것이 목표이고 , 이러한 목표에 도달하기위해서, 데이터 sampling을 진행하며, maximum likelihood estimation을 통해서 샘플링한 데이터를 가장 잘 설명하는 확률분포함수의 파라미터를 찾고자 합니다. 그래서 함수 값이 낮아지는 방향으로 독립 변수 값을 변형시켜가면서 최종적으로는 최소 함수 값을 갖도록 하는 gradient distance가 필요했던것이고 back propagation이 필요했던 것입니다.
Gradient descent
Gradient descent는 함수 값이 낮아지는 방향으로 독립 변수 값을 변형시켜가면서 최종적으로는 최소 함수 값을 갖도록 하는 독립 변수 값을 찾는 방법을 의미합니다. 함수의 최솟값을 찾기위해서는 미분계수가 0인 지점을 찾는 방식으로 진행 할 수도 있지만, 실제 분석에서 마주치는 함수들은 주로 non-linear function으로 이루어저 있기 때문에 미분 계수와 그 근을 계산하기가 어렵기 때문에, gradient descent를 사용합니다.

Back propagation
Backpropagation은 뉴럴넷을 학습시키기 위한 알고리즘 중 하나로써, 역전파라고도 합니다. 모델에서 내가 뽑고자 하는 target값과 실제 모델이 계산한 output이 얼마나 차이가 나는지 구한 후 그 오차값을 다시 뒤로 전파해가면서 각 노드가 가지고 있는 변수들을 갱신해 나가는 방식을 back propagation이라고 합니다.

Auto-Encoder
오토인코더는 입력을 받아서 복원을 하는 과정을 통해 학습을 진행하는 모델을 의미합니다. 예를들어 minist 748차원의 데이터가 인풋으로 주어졌을 경우, 차원축소를 진행후 다시 784차원의 데이터로 복원을 진행하는 압축과 해제를 하는 과정을 진행한다. 이러한 압축과 해제를 하는 과정에서 중요한 정보를 자연스럽게 학습이 됩니다.
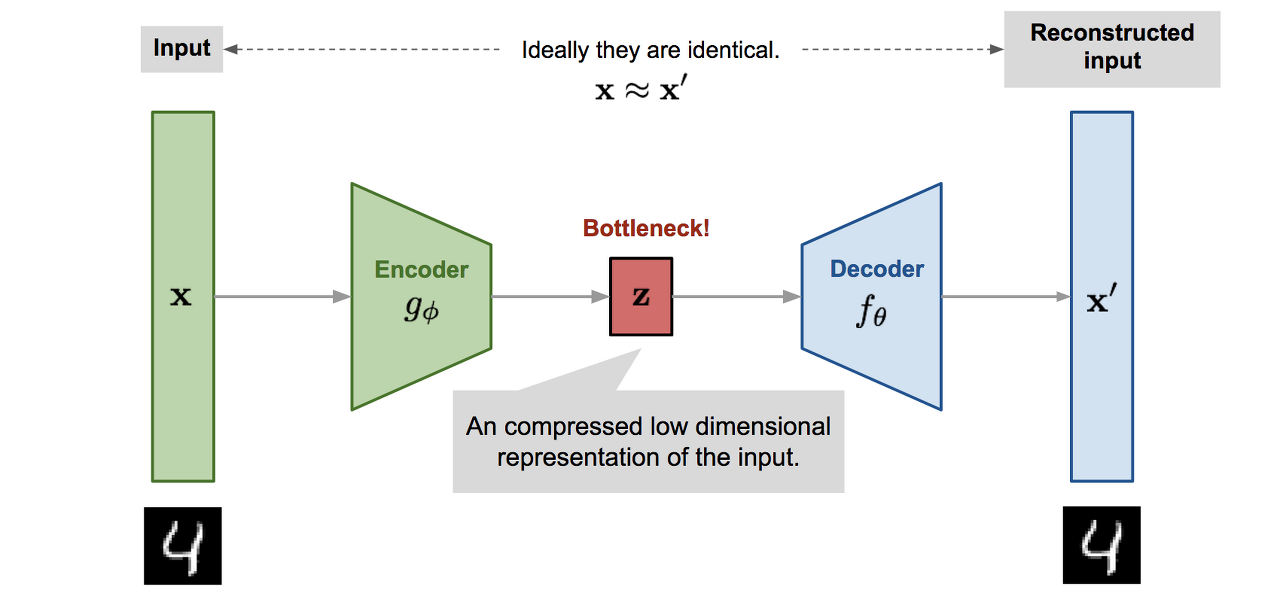
이러한 auto-encoder의 경우 x가 인코더를 통과하고 디코더를 통과할 때 x’ 이라는 복원샘플이 주어지게되고 NLP에서의 예를 들면 어떤 문장의 임베딩값을 input x로 넣었을 때, 그것의 핵심을 잘 표현해주는 representation z를 만들어주는 것입니다. 또한 decoder의 경우 encoder에서 이렇게 만들어준 z를 이용하여 다시 x를 reconstruct한 x’으로 바꾸어주는 기능을 한다. NLP외에도 auto-encoder 모델을 anomaly detection 혹은 novelty detion에도 활용 할 수 있는데, 정상 데이터 샘플을 활용해서 auto-encoder모델을 통해 학습을 시킨다음 x와 x’의 차이를 비교하여 차이가 크면 비정상, 작으면 정상으로 분류 할 수 도 있습니다. 압축과 해제과정을 진행해서 특징 추론 방법을 학습 하고 encoder 로 인해서 비 선형적인 차원축소 기능을 제공하고 또한 encoder와 decoder가 서로 협업을 통해 학습을 진행하기 때문에 학습에 용이하다는 장점을 지닙니다. 하지만 MSE 손실함수를 사용해서 복원성능이 떨어진다는 단점이 존재합니다. 예를들어 위의 그림처럼 Minist의 데이터 auto encoder를 통해 복원 샘플을 확인해보면 이미지가 매우 블러리 해진다는 점을 확인 할 수 있습니다,
NLP
자연어처리는 컴퓨터와 같은 기계장치를 이용해서 사람이 사용하는 언어를 이해하고, 생성 및 분석을 다룬 인공지능기술을 의미합니다. 즉, 즉 사람과 컴퓨터의 중간 인터페이스의 역할을 하는것이 NLP라고 할 수 있습니다. 여기서 컴퓨터가 인간이 만들어놓은 대량의 문서를 통해 정보를 얻는 방식을 NLU(Natural Language Understanding)이라고 하며, 얻어낸 정보를 사람이 이해핼 수 있게 사람의 언어로 표현하는것을 NLG(Natural Language Generation)이라고 합니다. 즉, 사람에서 컴퓨터로 갈때는 NLU이고 그 반대의 경우에는 NLG라고 할 수 있습니다. 이러한 일렬의 과정을 거치기 위해서 우리는 ML 이나 DL 모델을 활용할 수 있으며, 모델내 인풋의 경우 텍스트를 그대로 사용하기는 어렵습니다. 그래서 우리는 텍스트를 숫자로(백터화) 시키는 과정이 필요한데, 간단하게 encoding을 통해서 진행 할 수있습니다. Encoding 방식 중 대표적으로 one-hot encoding이 존재하나, 이는 단어간 유사도를 반영할 수 없다는 단점이 존재 합니다. 따라서 encoding 대신 embedding을 통해 단어간 유사도를 구할 수 있습니다. Word embedding의 경우 주변 단어(y)를 예측하기위해 필요한 정보를 현재 단어 에서 추출하여 압축하는 방식을 의미하며 word2vec의 경우 이러한 word embedding 방법중 하나 입니다. 그리고 sentecne embedding의 경우 lable(y)를 예측하기 위해 필요한 정보를 단어들의 시퀀스로부터 추출하여 압축하는 방식을 의미합니다.
언어모델이란?
언어모델은 문장의 확률을 나타낸 모델로, 문장 자체의 출현 확률을 예측하거나 이전 단어들이 주어졌을때 다음 단어를 예측하기위한 모델이라고 할 수있다. 궁극적인 목표는 우리가 일상 생활에서 사용하는 언어의 문장 분포를 정확하게 모델링 하는 것이다. 언어모델은 아래의 표와 같은 곳에서 쓰일수있습니다.
| Task | Description |
| Speech Recognition | Acoustic Model과 결합하여 인식된 음소의 시퀸스에 대해서 좀더 높은 확률을 갖는 시퀸스로 보안 |
| Machine Translation | 번역 모델과 결합하여 번역된 결과 문장을 자연스럽게 만듬 |
| Optical Character Recognition | 인식된 Character candidate sequence에 대해서 좀더 높은 확률을 갖는 sequence를 선택하는데 도움 |
| Other NLG Task | 뉴스 기사 생성, chatvot |
| Other | 검색어 자동 완성.. |
'머신러닝과 딥러닝' 카테고리의 다른 글
| ARIMA를 통한 시계열 데이터 분석 (0) | 2022.06.16 |
|---|---|
| Transfomer를 통한 시계열 데이터 예측 (5) | 2022.06.12 |
| 교차검증 (0) | 2022.03.02 |
| Confusion matrix (0) | 2022.02.21 |
| 랜덤포레스트(Random Forest) (0) | 2022.02.19 |

