
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 임베딩
- 사회연결망분석
- GCP
- topic modeling
- 허깅페이스
- degree centrality
- 구글클라우드플랫폼
- 동적토픽모델링
- word2vec
- 알파베타가지치기
- 머신러닝
- type-hint
- word representation
- sensibleness
- sbert
- dynamic topic modeling
- Meena
- ROC-AUC Curve
- Holdout
- QANet
- Enriching Word Vectors with Subword Information
- Google Cloud Platform
- hugging face
- semantic network
- 감성분석
- 토픽모델링
- sequential data
- 분류모델평가
- 의미연결망
- Min-Max 알고리즘
- Today
- Total
Dev.log
ARIMA를 통한 시계열 데이터 분석 본문
시계열 데이터는 일정한 시간동안 순차적으로 발생한 관측치의 집합이라고 할 수 있습니다. 이러한 시계열데이터는 고정된 시간구간의 관측치여야하며, 이는 시간구간이 규칙적이여야합니다. 즉, 시계열의 어느 구간은 daily, 다른 구간은 monthly와 같은 다양한 구간이 동시에 존재해서는 안됩니다.
Autoregressive Integrated Moving-Average Model
ARIMA 모델(Autoregressive Integrated Moving-Average Model)은 시계열 예측모델중 하나이며, 이전 포스팅인 Transformer를 통한 시계열 데이터 예측에서 간략하게 설명한 바 있습니다. 해당포스팅에서는 AR, MV, ARMA의 모델들에 대한 간단한 설명이 적혀있으니 해당 모델들이 궁금할시, 해당 포스팅에서 확인해 보실 수 있습니다.
Transfomer를 통한 시계열 데이터 예측
시계열 데이터란 시간에 대해 순차적으로 관측되는 데이터의 집합을 의미합니다. 일반적인 데이터 분석과정에서 독립변수(independent variable)를 이용해서 종속변수(dependent variable)을 예측하는 방
aboutnlp.tistory.com
ARIMA모델 같은 경우는 주가데이터와 같이 변동성이 심하며, 충격에 민감하고, 과거의 값에도 영향을 받는 시계열 모델일때 사용하실수 있는 모델입니다. 이러한, ARIMA (p,d,q) 모델은 다음과 같이 정의됩니다.
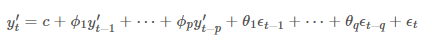
여기서 y'은 차분을 구한 시계열이며, p차 까지 AR처럼 과거의 y'값이 들어가 있으며, q차까지 MA처럼 ϵt가 전개되어있습니다. 즉, p는 AR 부분의 차수를 의미하며, d는 차분의 정도, 그리고 q는 MA부분의 차수라고 정의 할 수 있습니다. 만일 ARIMA(1,0,0) 이면 AR(1) 모형과 같으며 ARIMA(0,0,1) 이면 MA(1) 모형이 될 수 있습니다. 따라서, ARIMA(p,d,q) 모형은 어떤 시계열 데이터를 d차 차분을 했을 때, AR(p) 모형과 MA(q) 모형이 합쳐진 ARMA(p,q) 모형을 따르는 형태 입니다.

이를 후방이동(backshift) 연산자를 통해 정리해 보겠습니다.
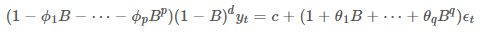
만약, d = 2 인 2차 차분이라면 아래와 같이 식을 구할 수 있습니다.

이처럼 ARIMA에는 p,d,q 값이 존재하며 해당 파라미터들을 잘 설정해 주어야하며 이를 AIC라고 하는 Akailke's information criterion이라는 아카이케 정보기준을 이용할 수 있습니다. AIC의 같은 경우 아래와 같이 정의할 수 있습니다.

여기서 log(L)은 로그의 가능도(likelihood; 후보 모형들로 모형을 세웠을 때 실체 관측된 데이터가 그 모형을 따를 확률)를의미하며, p는 추정된 모수의 갯수를 의미합니다. AIC의 식을 보면 −2log(L)으로 인해서, 모델이 잘 적합될수록 AIC 값은 작아지고, 2p로 인해 모델이 복잡할수록 AIC가 커지게 됩니다. 이 때 우리의 목적은 AIC를 최소화하는 모델을 고르는 것이기 때문에 가능도(likelihood)를 최대화하는 동시에 간단한 모델을 선택하게 됩니다. ARIMA모델에서도 p,d,q를 바꿔가면서 각 모델에 대한 AIC를 계산할 수 있습니다. 이를 식으로 표현하면 아래와 같습니다.

이와같이 AIC와 같은 정보기준을 통해 시계열 값을 잘 설명할 수 있는 p,d,q를 추정할 수 있습니다. Python에서는 pmdarima 내 auto_arima를 통해 자동으로 p, d, q를 수정하면서 계수를 추정하고 각 모형별로 최적의 값을 계산합니다.
ARIMA를 통한 시계열 데이터 분석
주가데이터와 유사한 다우지수는 변동성이 심하며, 충격에 민감하고, 과거의 값에도 영향을 받기때문에 ARIMA를 통해 분석을 진행해 볼 수 있습니다. 따라서, 파이썬내 yfinance 패키지를 통해 다우지수의 2021년 1월 부터 12월까지, 총 1년치의 데이터를 불러왔습니다.
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
data = pdr.get_data_yahoo('^DJI','2021-01-01','2021-12-31')
data.tail(3)
다우지수의 2021년 1월 부터 12월까지의 시계열 데이터중 시초가(Open)를 확인해 보겠습니다. 그리고 시계열 예측을 위해 8:2의 비율로 데이터를 분류해 주었습니다.
plt.figure(figsize = (10,5))
y_train = data['Open'][:int(0.8*len(data))]
y_test = data['Open'][int(0.8*len(data)):]
y_train.plot()
y_test.plot()
이후 해당 시계열에 대해 분해를 진행해 보도록 하겠습니다. Python에서는 statsmodels이라는 라이브러리를 제공해 주며, 해당 라이브러리 내에서 seasonal_decompose()를 통해 시계열 분해를 진행 할 수 있습니다. 이를통해 2021년 1월부터 12월까지의 다우지수 시계열 데이터에 대해 분해를 진행하였으며, 다우지수의 경우 한 주에 거래일수가 5일, 한달에 거래일수가 20일, 그리고 1년에 253일이 존재하기때문에, 이를 위해 period를 5, 20, 253으로 조정후 테스트를 진행했고 period를 20으로 조정하였을떄 p값이 가장 작았음을 확인했습니다. 따라서 period를 20으로 조정하고 시계열 분해를 진행한 결과는 아래와 같습니다.
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(data['Open'],
model = 'additive',
period = 20)
fig = plt.figure()
fig = result.plot()
fig.set_size_inches(10,10)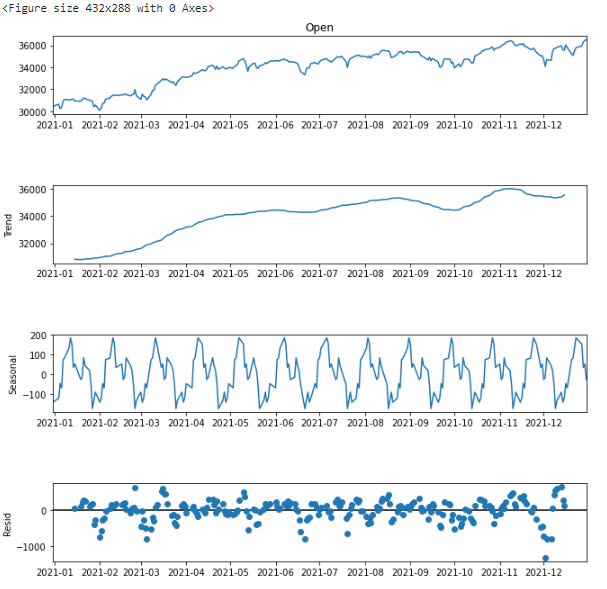
먼저 해당 데이터를 보면 정상성은 만족하지 않는다고 의심을 할 수 있습니다.이를 판단하기위해 ACF(자기상관함수, AutoCorrelation Function)를 통해 확인해 보았습니다.
import statsmodels.api as sm
fig = plt.figure(figsize = (10,5))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(data['Open'], lags = 20, ax = ax1)
위의 ACF(자기상관함수, AutoCorrelation Function)를 확인해 보면 해당 값이 천천히 감소하는 것을 확인 할 수 있으며, 이는 정상성을 만족하지 않는 다고 할 수 있습니다. 정상성을 만족하지 않는다는것을 단위근 검정인 ADF(Augmented Dickey-Fuller test)로 다시한번 확인해 보겠습니다. ADF검정의 가설을 세워보면, 귀무가설의 경우 자료의 단위근이 존재한다와 대립가설은 자료가 정상성을 만족한다로 세울수 있습니다.
from statsmodels.tsa.stattools import adfuller
result = adfuller(data['Open'])
print('ADF Stats : %f' % result[0])
print('P val : %f' % result[1])
print('Critical Values : ')
for i, v in result[4].items():
print(i,v)
>>> ADF Stats : -1.714473
>>> P val : 0.423671
>>> Critical Values :
1% -3.4566744514553016
5% -2.8731248767783426
10% -2.5729436702592023ADF를 진행해본결과 p값이 0.05를 넘기때문에 귀무가설을 기각하지 못하게 됩니다. 즉 해당 데이터는 정상성을 만족하지 못한다 라고 할 수 있습니다. 따라서 이러한 정상성을 해결하고자 차분을 진행해 주어야하며, ARIMA의 차수가 1 이상이겠다라고 예상해 볼 수있습니다. 따라서 얼마만큼의 차분이 최선인지 알아보기위해, pmdarima.arima라이브러리에서의 ndiff를 통해 알아 보았습니다.
from pmdarima.arima import ndiffs
import pmdarima as pm
kpss_diffs = ndiffs(y_train, alpha=0.05, test='kpss', max_d=6)
adf_diffs = ndiffs(y_train, alpha=0.05, test='adf', max_d=6)
n_diffs = max(adf_diffs, kpss_diffs)
print(f"차수 d = {n_diffs}")
>>> 차수 d = 1ndiff를 통한 차수의 값은 1임을 알 수 있고, 1차 차분한 데이터의 정상성을 확인하기 위해 ADF(Augmented Dickey-Fuller test)를 다시한번 진행해 주었습니다.
diff = data['Open'] - data['Open'].shift()
result = adfuller(diff[1:])
print('ADF Stats : %f' % result[0])
print('P val : %f' % result[1])
print('Critical Values : ')
for i, v in result[4].items():
print(i,v)
>>> ADF Stats : -15.177788
>>> P val : 0.000000
>>> Critical Values :
1% -3.456780859712
5% -2.8731715065600003
10% -2.572968544ADF를 진행해본결과 p값이 0.05보다 작기 때문에 귀무가설을 기각할 수 있습니다. 즉 1차 차분한 데이터는 정상성을 만족한다고 할 수 있습니다. 이제 1차 차분한 데이터를 통해 auto_arima를 통해 최적의 모형을 탐색해 보겠습니다. 앞서 말했듯, train과 test 데이터셋의 비율은 8:2로 나누어 주었으며, train 데이터를 통해 학습을 진행하고 teset데이터로 예측을 진행해보도록 하겠습니다.
stepwise_model = pm.auto_arima(y_train,
d = 1,
start_p = 0,
start_q = 0,
max_p = 7,
max_q = 7,
seasonal=False,
suppress_warnings=True,
stepwise=False)
stepwise_model.fit(y_train)
모델에 대한 결과값을 plot_diagnostics()를 통해 얻은 잔차 그래프로도 확인해보겠습니다.
stepwise_model.plot_diagnostics(figsize=(16, 8))
plt.show()
잔차가 백색 잡음을 따르는지 보여주는 그래프는 (1,1)과 (2,2)에 위치한 그래프입니다. (1,1)은 잔차를 그냥 시계열로 그린것이며, (2,2)는 잔차에 따른 ACF입니다, 이를통해 시계열이 평균 0을 중심으로 무작위하게 움직이는 것을 확인 할 수 있고, ACF도 허용범위안에 위치함을 확인 할 수 있습니다. 잔차가 정규성을 만족하는지 보여주는 그래프는 (1,2)와 (2,1)에 위치한 그래프입니다. (1,2)는 잔차의 히스토그램을 그려 정규 분포 N(0,1)과 밀도를 추정한 그래프를 같이 겹쳐서 보여줍니다. (2,1)그래프는 Q-Q 플랏으로 정규성을 만족한다면 빨간 일직선 위에 점들이 분포해야 합니다. 그러나, 양 끝 쪽에서 빨간 선을 약간 벗어나는 듯한 모습을 확인할 수 있습니다.
이러한 모델의 예측된 결과물은 아래의 코드를 통해 확인해 볼 수 있습니다.
# 테스트 데이터 개수만큼 예측
y_predict = stepwise_model.predict(n_periods=len(y_test))
y_predict = pd.DataFrame(y_predict,index = y_test.index,columns=['Prediction'])
# 그래프
fig, axes = plt.subplots(1, 1, figsize=(12, 4))
plt.plot(y_train, label='Train') # 훈련 데이터
plt.plot(y_test, label='Test') # 테스트 데이터
plt.plot(y_predict, label='Prediction') # 예측 데이터
plt.legend()
plt.show()'머신러닝과 딥러닝' 카테고리의 다른 글
| DBSCAN - 밀도 기반 클러스터링 (0) | 2022.08.08 |
|---|---|
| Process Mining - 프로세스 마이닝 (0) | 2022.08.08 |
| Transfomer를 통한 시계열 데이터 예측 (5) | 2022.06.12 |
| Deep Neural Network (0) | 2022.05.31 |
| 교차검증 (0) | 2022.03.02 |

