
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 분류모델평가
- QANet
- Meena
- topic modeling
- degree centrality
- 머신러닝
- 알파베타가지치기
- Enriching Word Vectors with Subword Information
- Min-Max 알고리즘
- 구글클라우드플랫폼
- word2vec
- GCP
- type-hint
- semantic network
- sensibleness
- 임베딩
- 허깅페이스
- hugging face
- 동적토픽모델링
- sequential data
- word representation
- Google Cloud Platform
- 감성분석
- dynamic topic modeling
- ROC-AUC Curve
- Holdout
- 의미연결망
- 사회연결망분석
- sbert
- 토픽모델링
- Today
- Total
Dev.log
Transfomer를 통한 시계열 데이터 예측 본문
시계열 데이터란 시간에 대해 순차적으로 관측되는 데이터의 집합을 의미합니다. 일반적인 데이터 분석과정에서 독립변수(independent variable)를 이용해서 종속변수(dependent variable)을 예측하는 방법이 일반적이라면, 시계열 데이터 분석은 시간을 독립변수로 활용한다고 이해하면 될것 같습니다.이러한 시계열 데이터의 예시로는 센서 데이터, 주식 데이터, 스트림 데이터 등이 존재합니다. 시계열데이터는 기록 추세, 실시간 경고 등과 같은 예측 모델링을통해 분석을 할 수 있습니다.
- Abrupt Change : 데이터가 가파른 변동을 보이는지
- Outliers : 다른 값들과 동떨어진 Outlier가 관측되는지
- Trend : 측정 값이 시간의 흐름 에 따라 증감, 반복을 하는 일정한 Pattern, 경향이 있는지
- Seasonality : 일, 월, 년, 계절 등 일정 시간에 따라 지속해서 반복되는 Pattern이 있는지
- Constant Variance : 측정값이 일정한 수준 이내로 변동되는지, 변동이 랜덤하게 발생하는지
- Long-run Cycle : 오랜 기간 반복되는 Pattern이 있는지
전통적으로 시계열 예측은 현재 시점까지 데이터의 확률적 특성이 시간이 지나도 그대로 유지 될 것을 가정하고 있습니다. 즉, 시간과 관계 없이 평균과 분산이 불변해야하고, 두 개의 시점 간의 공분산이 다른 시점 과는 무관해야 한다고 할 수 있습니다. 통계학적으로 시계열 데이터 예측에서는 AR(Autoregressive), MA(Moving average), ARMA(Autoregressive Moving average), ARIMA(Autoregressive Integrated Moving average) 모델 등을 활용해 불규칙적인 시계열 데이터에 규칙성을 부여하는 방식을 활용해왔었습니다. 딥러닝 모델을 통한 시계열 예측에 들어가기 앞서, 간단하게 AR, MA, ARMA, ARIMA 방식들에 대해 설명드려 보도록 하겠습니다.
AR(Autoregressive)
Autoregressive 모델은 자기 회귀 모델이라고 불립니다. 이러한 자기회귀 모델에서는 변수의 과거 값의 선형 조합을 이용하여 관심 있는 변수를 예측합니다. 즉 과거 시점의 자기 자신의 데이터가 현 시점의 자기 자신에게 영향을 미치는 모델이라고 이해할 수 있을것 같습니다. 자기회귀(autoregressive)라는 단어에는 자기 자신에 대한 변수의 회귀라는 의미가 있습니다. 따라서, 차수 의 자기회귀 모델(autoregressive models)은 다음과 같이 쓸 수 있습니다.
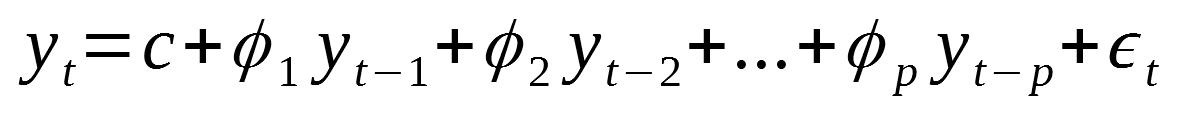
여기에서 는 백색잡음(백색잡음은 평균이 0이고 분산이 일정한 상수(σ2)인 정규분포를 따르며, 시간에 흐름에 따른 다른 백색잡음들과 correlation이 0인 잡음)입니다. 의 시차 값을 예측변수(predictor)로 다루는 것만 제외하면 다중 회귀처럼 생겼습니다.
MA(Moving average)
Moving average 모델은 이동 평균 모델이라고 불리고, 어떤 것이 방향성을 가지고 움직일때 이동하면서 구해지는 평균을 의미한다고 할 수 있습니다. 즉 동적으로 변화하는 과정에서는 이러한 이동평균방식을 적용시킬수 있습니다. 이번 포스팅에서는 transformer모델을 통해 주가 데이터를 예측하고자 하지만, 이동평균역시 1차원적인 방향성를 가지고 이동하기 때문에 이동평균을 통한 예측을 할 수 도있습니다. 이동평균의 경우, 기본적인 simple moving average부터 시간의 변화에 따라 weight를 weightage movinga average, 그리고 exponentail moving average가 존재합니다. 이러한 MA 방법들을 식으로 표현하면 아래와 같이 나타낼 수 있습니다.
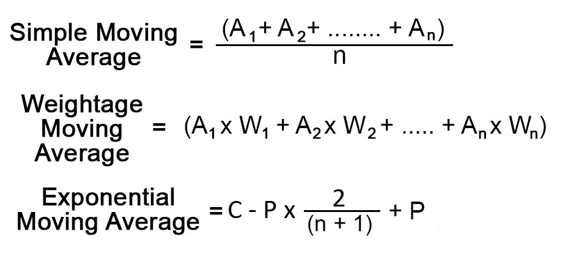
ARMA(Autoregressive Moving average)
ARMA의 같은경우 Autoregressive 와 moving average를 합친것으로 현재 시점의 상태를 파악하는 과거 시점의 자기 자신과 추세까지 전부 반영하여 예측을 진행하는 모델이라고 생각 할 수 있습니다. 이를 식으로 표현하면 아래와 같이 나타낼 수 있습니다.

ARIMA(Autoregressive Integrated Moving average)
AR, MA, ARMA모델의 경우 시계열이 정상성이라는 가정이 있는 상황에서 분석을 진행하는 모델이라고 생각 할 수 있습니다. 반면 현실세계에서의 시계열 데이터는 non-stationary한 특성을 지니고 있습니다. ARIMA모델의 경우 차분이라는 개념을 통한 이러한 non-stationary한 상황에서 좀더 나은 예측을 하는것을 목표로 하고있다 라고 생각할수 있을것 같습니다. 따라서 ARIMA에서는 차분이라는 차수 d가 포함되며 ARIMA(p,d,q)로 표현할 수 있습니다. 여기서 차분이라는 개념은 현재 상태에서 바로 이전 상태를 빼주는 것을 의미하며, 차분을 거친 결과들이 whitening되는 효과를 가져온다. 이러한 차분을 수식으로 보면 아래와 같이 나타낼수 있습니다.

결국 1차분이 필요한 ARIMA(1,1,1)모델의 경우 ARMA(1,1)모델의 수식에서 X위치에 1차분이 들어간 식을 대입해주면 됩니다.
Transfomer 모델을 통한 시계열 데이터 예측
머신러닝 방식과 통계적 방식 모두 시계열 예측에서의 목표는 sum of squared error와 같은 손실함수를 최소화 하여 예측 정확도를 향상시키는 것입니다. 통계적 방법의 경우 대부분 선형처리를 진행을해서 손실함수를 최소화하며 머신러닝은 비선형 처리를 통해 손실함수를 최소화 하는 방법을 채택하고있습니다. 딥러닝의 경우 RNN종류의 LSTM(Long-Short Term Memory)이 시계열 예측 tak에서 좋은 성능을 내고있습니다. 이번 포스팅에서는 LSTM모델이 아닌 자연어 처리에서 뛰어난 성능을 보이는 Transformer를 통해 시계열 예측을 진행해 보고자 합니다. 먼저, 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델입니다. 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였으며 자연어처리 task에서 기존의 RNN 보다 높은 성능을 보여주었습니다. 이러한 트랜스포머의 모델 구조는 아래와 같이 나타납니다.

이러한 트랜스포머의 작동 방식을 짧게 설명하자면, 트랜스포머의 입력값은 인코더에 입력이 됩니다. 입력값이 인코더에 입력이되면 각 토큰들은 포지셔널 인코딩과 더해지고 인코더는 이 값들을 행렬계산을 통해서 한번에 어텐션 백터를 생성해 냅니다. 어탠션백터는 토큰의 의미를 구하기 위해서 사용이 됩니다. 예를들어 단어 하나만 보면 단어의 의미가 상당히 모호할때가 많은데, 예를들어 문장 전체를 보지 않고 text라는 단어만을 보면 text가 신문속에 있는 문장들을 의미하는지 문자메세지를 보내는 행위를 의미하는지 이해하기 어렵습니다. 어텐션은 각각의 토큰들은 문장속의 모든 토큰을 봄으로써 각 토큰의 의미를 정확하게 모델에 전달하게 됩니다. 어탠션 백터는 FC 레이어로 전달이 되며 이와 동일한 과정이 6번 진행이 됩니다. 그리고 이러한 최종 출력값은 디코더의 인풋으로 들어가게 됩니다. 그리고 디코더는 인코더의 출력값과 최초 스타트 스페셜 토큰으로 작업을 시작합니다. 디코더는 왼쪽 부터 오른쪽으로 순차적으로 출력값을 생성하고 이전 생성된 디코더의 출력값과 인코더의 출력값을 사용해서 현재의 출력값을 생성합니다. 디코더 역서 어탠선 벡터를 생성하고 FC 레이어로 보내는 과정을 반복합니다. 디코더는 end-token이라는 토큰을 출력할때까지 반복이 됩니다. 그리고 이러한 transformer의 인코더의 부분은 자연어 처리에서 유명한 BERT, 그리고 디코더에서 파생된 모델로는 대표적으로 GPT가 있습니다.
이렇듯, 트랜스포머는 자연어 처리와 컴퓨터 비전 task 에서 역시 우수한 성능을 달성했으며 이는 시계열 task에서도 트랜스포머의 여러 장점 중 장거리 종속성과 상호 작용을 capture하는 기능은 시계열 모델링에 매력적이라 판단되어 Transformer가 시계열 예측에서도 좋은 성능을 보이는지 확인해 보기 위해 Transformer 모델을 이용하여 시계열 예측을 진행해 보겠습니다.
먼저 KOSIP 지수를 불러오기 위해 pykrx 패키지를 통해 데이터를 불러와보았습니다. 주가데이터의 경우 전체 코스피 지수가 아닌, 2010년 01월 01일 부터 2021년 12월 31일 까지의 데이터를 사용하였습니다
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pykrx import stock
df = stock.get_index_ohlcv_by_date("20100101", "20211231", "1001")
plt.figure(figsize=(20,5))
plt.plot(range(len(df)), df["종가"])
이후 sklearn의 MinMaxSclaer를 사용하여 데이터의 범위를 0~1로 변환시켜준 후 train, test set을 나누어 주었습니다.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
df["종가"] = min_max_scaler.fit_transform(df["종가"].to_numpy().reshape(-1,1))이후 Pytorch의 nn.transformer를 사용해서 트랜스포머 모델의 인코더와 디코더를 생성해주었습니다. 또한 시계열 예측을 위해 데이터의 일정한 길이의 input window, output window를 설정하고, 데이터의 처음 부분부터 끝부분까지 sliding 시켜서 데이터셋을 생성하여 트랜스포머 모델에 활용할 수 있는 데이터셋을 만들어 주었습니다.
from torch.utils.data import DataLoader, Dataset
class windowDataset(Dataset):
def __init__(self, y, input_window=80, output_window=20, stride=5):
L = y.shape[0]
num_samples = (L - input_window - output_window) // stride + 1
X = np.zeros([input_window, num_samples])
Y = np.zeros([output_window, num_samples])
for i in np.arange(num_samples):
start_x = stride*i
end_x = start_x + input_window
X[:,i] = y[start_x:end_x]
start_y = stride*i + input_window
end_y = start_y + output_window
Y[:,i] = y[start_y:end_y]
X = X.reshape(X.shape[0], X.shape[1], 1).transpose((1,0,2))
Y = Y.reshape(Y.shape[0], Y.shape[1], 1).transpose((1,0,2))
self.x = X
self.y = Y
self.len = len(X)
def __getitem__(self, i):
return self.x[i], self.y[i]
def __len__(self):
return self.leniw = 24*14
ow = 24*7
train_dataset = windowDataset(data_train, input_window=iw, output_window=ow, stride=1)
train_loader = DataLoader(train_dataset, batch_size=64)이후 Transforemer 모델에서 decoder는 사용하지 않았으며 encoder의 아웃풋에 FC 레이어르 연결해서 시계열 예측 모델을 만들어 주었습니다.
class TFModel(nn.Module):
def __init__(self,iw, ow, d_model, nhead, nlayers, dropout=0.5):
super(TFModel, self).__init__()
self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=nlayers)
self.pos_encoder = PositionalEncoding(d_model, dropout)
self.encoder = nn.Sequential(
nn.Linear(1, d_model//2),
nn.ReLU(),
nn.Linear(d_model//2, d_model)
)
self.linear = nn.Sequential(
nn.Linear(d_model, d_model//2),
nn.ReLU(),
nn.Linear(d_model//2, 1)
)
self.linear2 = nn.Sequential(
nn.Linear(iw, (iw+ow)//2),
nn.ReLU(),
nn.Linear((iw+ow)//2, ow)
)
def generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def forward(self, src, srcmask):
src = self.encoder(src)
src = self.pos_encoder(src)
output = self.transformer_encoder(src.transpose(0,1), srcmask).transpose(0,1)
output = self.linear(output)[:,:,0]
output = self.linear2(output)
return output
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
def gen_attention_mask(x):
mask = torch.eq(x, 0)
return mask이후 학습을 진행시켜 주었습니다.
device = torch.device("cuda")
lr = 1e-4
model = TFModel(24*7*2, 24*7, 512, 8, 4, 0.1).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
epoch = 500
model.train()
progress = tqdm(range(epoch))
for i in progress:
batchloss = 0.0
for (inputs, outputs) in train_loader:
optimizer.zero_grad()
src_mask = model.generate_square_subsequent_mask(inputs.shape[1]).to(device)
result = model(inputs.float().to(device), src_mask)
loss = criterion(result, outputs[:,:,0].float().to(device))
loss.backward()
optimizer.step()
batchloss += loss
progress.set_description("loss: {:0.6f}".format(batchloss.cpu().item() / len(train_loader)))이를 통해 모델을 확인해보면, 아래 차트처럼 결과값이 나온것을 확인 할 수 있습니다.
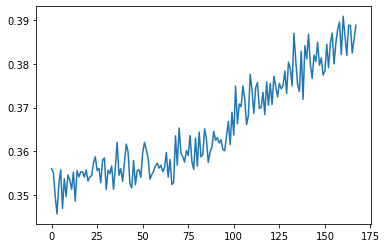
'머신러닝과 딥러닝' 카테고리의 다른 글
| Process Mining - 프로세스 마이닝 (0) | 2022.08.08 |
|---|---|
| ARIMA를 통한 시계열 데이터 분석 (0) | 2022.06.16 |
| Deep Neural Network (0) | 2022.05.31 |
| 교차검증 (0) | 2022.03.02 |
| Confusion matrix (0) | 2022.02.21 |

